

对于当下这些主流级别、价格要远比我们当初那两台老电脑低得多的「轻薄核显本」来说,它们又是否能够让用户也享受到本地大模型所带来的便利呢?
【【【前言:测过「非 AI PC」后,我们又来折腾核显轻薄本了】】】
前段时间,我们三易生活出于技术层面的好奇心,尝试使用两台不具备 NPU 的「老电脑」运行了一些 AI PC 时代的软件,并撰写了《用「非 AI PC」运行 AI 应用后,我们发现了这些真相》。
结果我们发现,由于 CPU 和 GPU 上的「AI 加速指令集」以及「AI 加速单元」实际上诞生的时间,要远早于 AI PC 这个概念,以至于在刻意使用较老的 PC 硬件时,它们依然能够在不少「AI PC 专用软件」里得到适配,使用 CPU 或 GPU 来实现基于本地大模型的问答、写作、知识归纳和绘图等功能。

但也正因如此,当时我们就已经发现,对于手头的老电脑来说,它们之所以能够做到这一点,一方面是因为我们用的酷睿处理器、ARC 独显本身,就得到了来自 Intel 的 OpenVINO AI 加速体系的适配。换句话说,这甚至可以看作是 Intel 在「AI 时代」对于自家上一代、甚至前两三代硬件平台给予的「温情」。
但从另一方面来说,大家都知道,如今消费者能够实际买到的轻薄(非游戏)本,它们虽然通常都多了个 NPU 单元,但同时这些产品也往往不再像我们之前使用的那些机型一样,还额外内置了带有 AI 单元的独立显卡。

那问题就来了,对于当下这些主流级别、价格要远比我们当初那两台老电脑低得多的「轻薄核显本」来说,它们又是否能够让用户也享受到本地大模型所带来的便利呢?
【【【基础测试:GPU 和 NPU 都能跑 AI,文本生成指标意外地快】】】
为了探究这个课题,我们三易生活此次找来了一款最近才刚刚发布、基于 Intel Arrow Lake-H 平台的核显轻薄本——荣耀 MagicBook Pro 14,并基于它进行了一系列的本地化 AI 实操与测试。

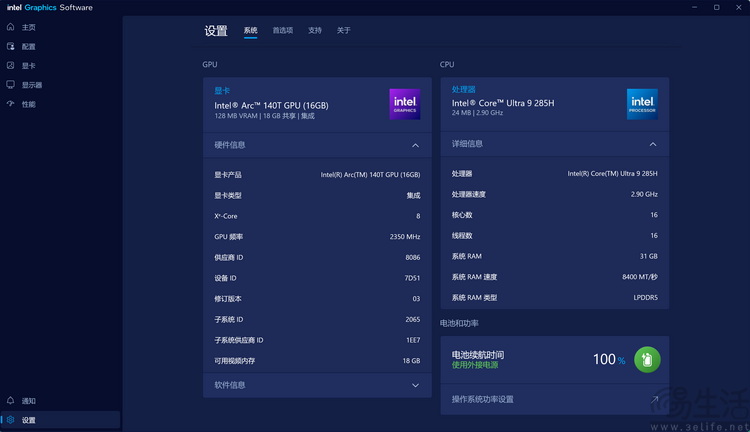
首先「验明正身」,此次我们准备的是荣耀 Magic Book Pro 14 的顶配版本,其搭载的是酷睿 Ultra9 285H 处理器,并配有 32GB 的 LPDDR5X 8533MHz 内存以及 1TB 的长江存储 PC401 SSD。它没有独立显卡,而是依靠集成的 ARC 140T 核显,同时 CPU 内集成了基于 Moviduis VPU3720(即 Intel NPU3)方案的 NPU 加速器。

按照惯例,同时也是为了与此前测试的那两台老电脑进行软件环境的「统一」,在测试开始前,我们先将操作系统、核显,以及 NPU 的驱动都更新到了最新版本。
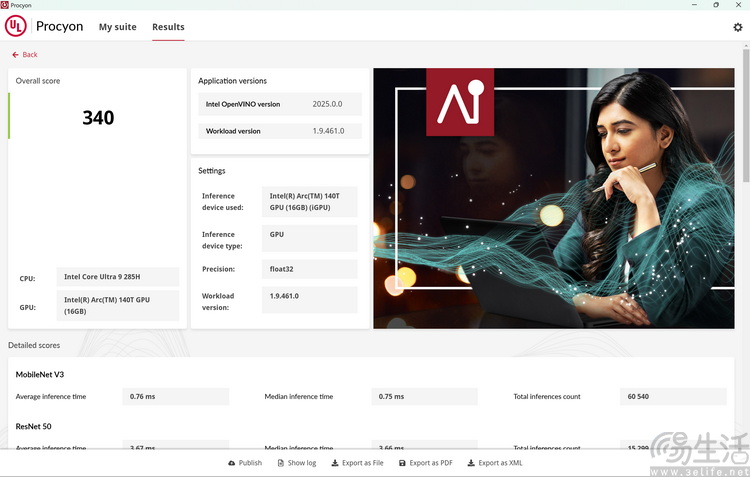

接下来,我们使用 Procyon 套件对这款核显轻薄本进行了部分端侧 AI 计算场景的性能测试。可以看到,Arrow Lake-H(下文将简称为 ARL-H)的 GPU 与 NPU 都支持计算机视觉(也就是摄像头相关)的 AI 加速运算。考虑到 Intel 的「NPU3」原本就是基于 Moviduis VPU 架构实现,所以这也在我们的意料之中。
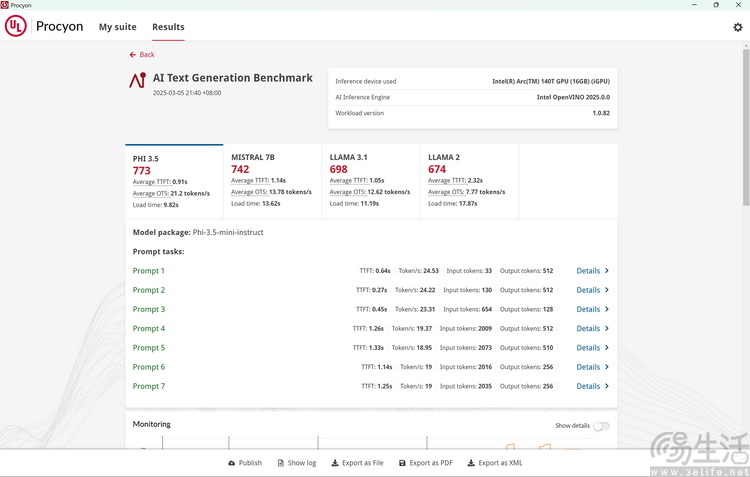
在 Procyon 的文本生成测试中,则自动选择了 ARC 140T 核显作为 AI 加速器。可以看到在多个测试任务中,ARL-H 平台的这颗核显现在居然都能跑出 20 Tokens/s 的生成效率。简单来说,这个生成速度已经完全可以满足「对答如流」的用户体验了。
此前有看过我们三易生活相关内容的朋友可以记得,这是因为 ARL-H 里的这颗 ARC 140T 核显虽然本质上还是源自初代 Xe 架构,但它重新加入了此前在 MTL-H 平台上因为面积因素而被取消的 GPU XMX 单元。就结论而言,这就使得 ARC 140T 在核心规模方面,实际上无限接近此前的独显版本 ARC A370M。甚至对比 ARC A370M,它的着色器频率还要更高,再加上 128bit、32GB 的 8533MHz 内存,即便是共享显存,带宽和容量也都反超了 A370M 的 4GB、64bit 独立显存。
【【【实际运用:本地部署 Deepseek 很简单,甚至还能更无脑】】】
不过光有 Procyon 的跑分显然还不足以说明问题,所以我们还从魔搭社区下载了专为 Intel 平台优化过的 Ollama 对话模型,并基于它在这台 MagicBook Pro 14 上尝试进行了 Deepseek-R1 7B 的本地部署。
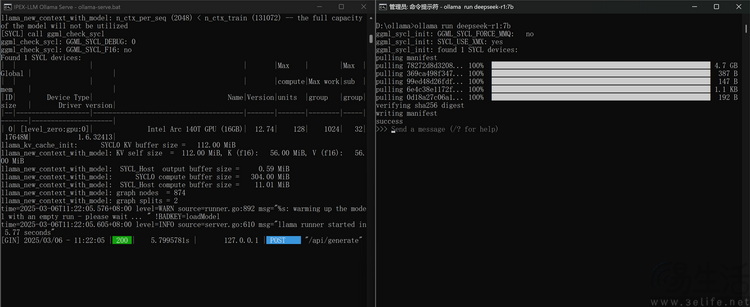
实际上,部署过程可以说相当「无脑」。只需将下载的压缩包解压,之后从 CMD 内将其启动,再使用命令行指定下载 Deepseek-R1 7B,等自动化的下载和安装完成之后,就可以开始对话了。
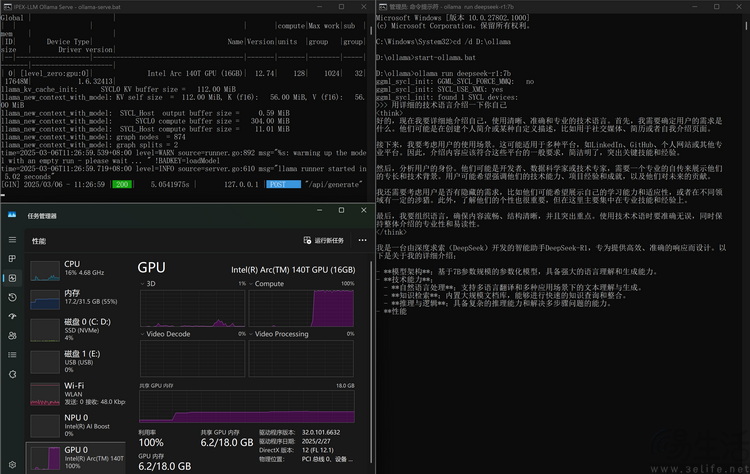
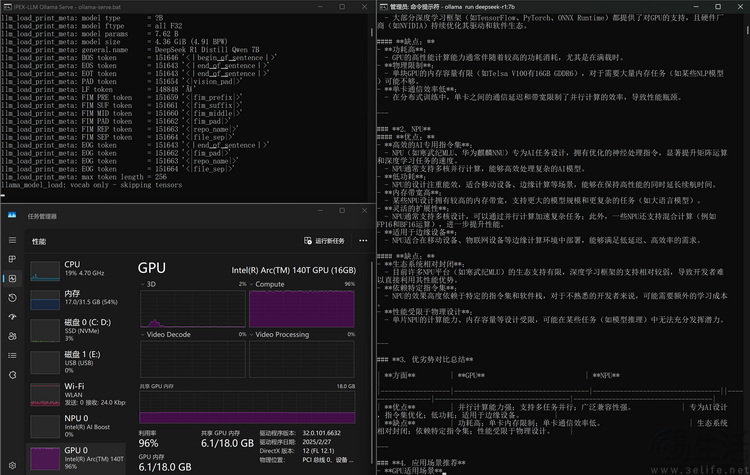
从运行效果来看,Ollama 完全可以只靠 ARC 140T 核显的计算单元,来运行 Deepseek-R1 7B 这个本地大模型。在运行过程中,它的共享显存甚至也才用到 1/3 左右。而其回复速度和回复的复杂度,更是完全具备可用性。
当然,众所周知的是,Ollama 因为没有 UI,所以在使用的便利性上确实不算高,特别是对普通用户还是不够友好。但好在现在也有一些第三方软件已经针对酷睿 Ultra 平台做了专门的适配。只要软件侦测到处理器符合特定的型号,就会自动「解锁」相应的本地 AI 处理模式。
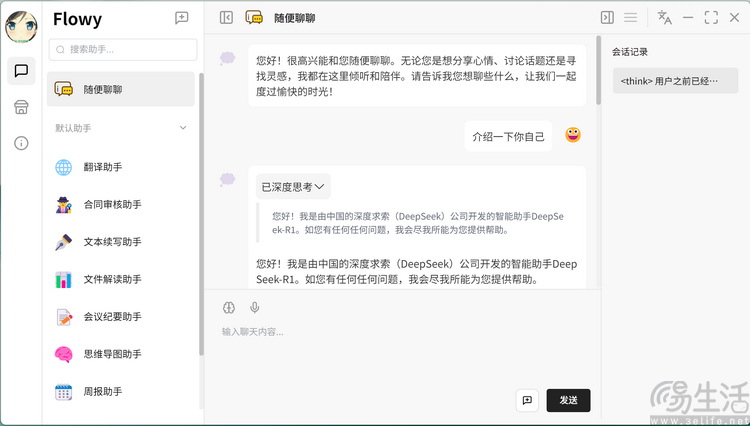
以 Flowy 为例,它本身就自带云端和本地两种大模型工作模式。在我们此前测试的「非 AI PC」上,本地大模型虽然可以下载,但无法在对话模式下被选中。而到了酷睿 Ultra 平台,Flowy 就允许用户切换到本地模型工作状态。
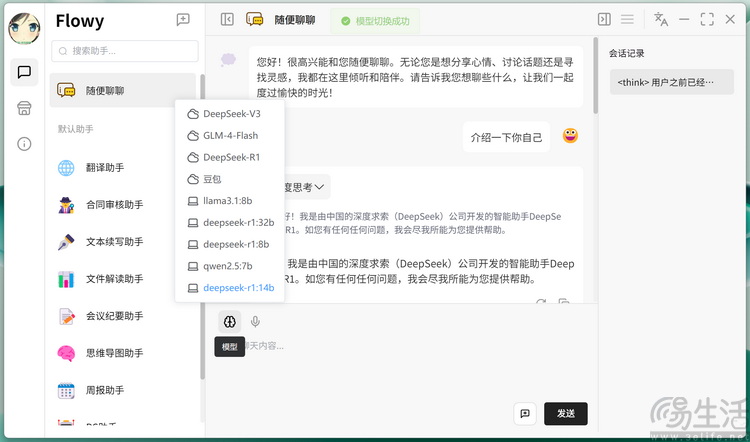
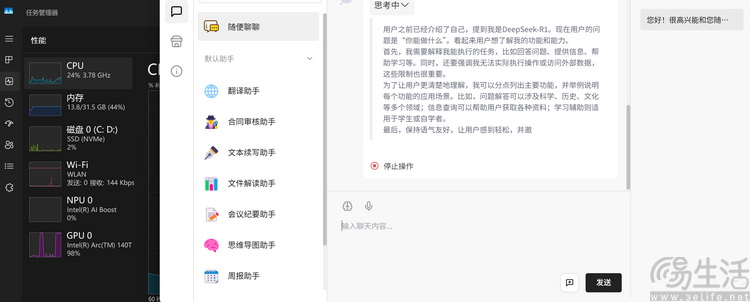
从我们实测结果来看,Magic Book Pro 14 搭载的酷睿 Ultra9 285H 处理器搭配 32GB 高频内存,甚至可以「带动」14B 规模的 Deepseek 本地大模型,在回答精度和使用便利度上都要比 Ollama 更上一层楼。

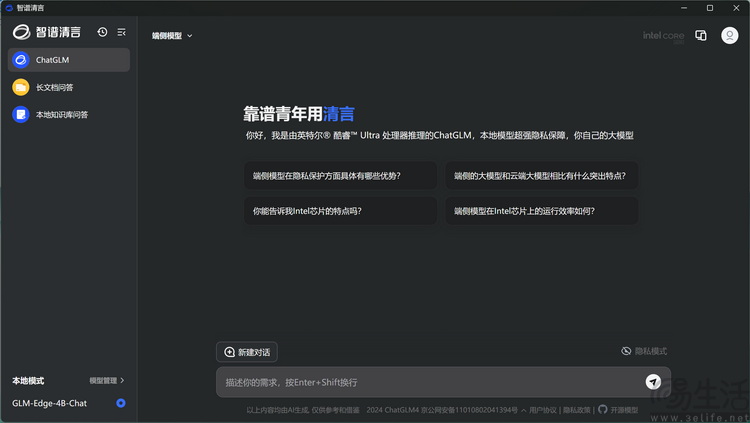
除了 Flowy,另一个 AI 对话 APP「智谱清言」对于酷睿 Ultra 平台的适配就做得更有意思。在首次启动后,它会提示可以切换到专为 Intel 酷睿 Ultra 平台适配的本地对话模式。此时,不仅原本隐藏的本地模型下载功能会自动「解锁」,甚至就连软件本身的界面都会发生改变,右上角会出现「Intel Core Ultra」的 Logo,让人一眼就能看出它是专为目前的处理器做了适配。
【【【结语:AI PC 的真正意义,在于让更多人能够用得到】】】
其实很早之前我们三易生活就曾指出,在整个 PC 行业中,Intel 可能才是对于 AI PC 响应最早,而且实际产品覆盖面最广的品牌。

因为从一方面来说,通过我们此前对那两台「非 AI PC」的测试已经证明,即便是几年前的 Intel 处理器和显卡,也能受益于它们早早就内含的 DLBoost、XMX 等指令集和计算单元,在最新的 API 下被用于 AI 软件的加速处理。
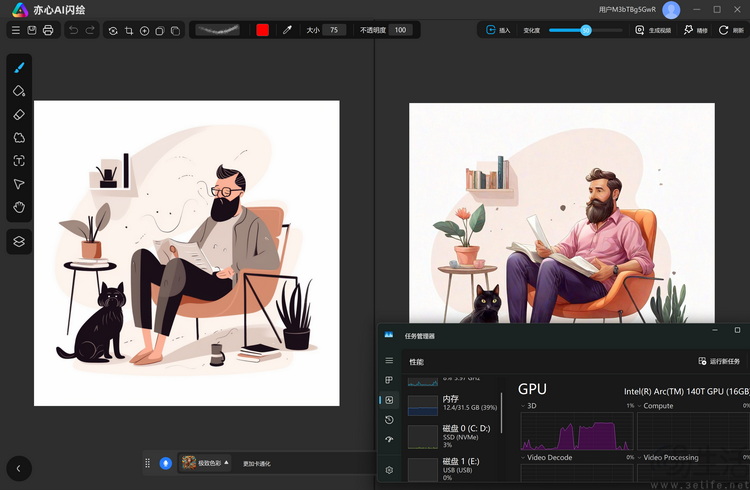
亦心闪绘在酷睿 Ultra 平台可以使用 GPU 和 NPU 实现交互式的图生图
另一方面,针对最新一代的 Arrow Lake-H 平台,Intel 不仅为其配备了高性能的 CPU、GPU、NPU,更重要的是他们还在积极地推动第三方 AI 软件的适配。即便是没有独立显卡的「轻薄本」,只要使用了 Arrow Lake-H、LunarLake-MX 等 Intel 最新世代的 AI PC 硬件,那么都可以在诸如知我 AI、Flowy、智谱清言、亦心闪绘等一系列 AI 软件中,自动得到针对 GPU、NPU 的 AI 加速适配。

如此一来,哪怕是完全不懂得何谓「部署」、何谓「调优」的普通消费者,实际上在最新的这些 Intel AI PC 平台、特别是轻薄型的笔记本电脑上,就都能受益于无门槛的本地大模型。而这不仅仅是对于消费者来说意义重大,更为重要的是,相比那些看似很强大、但需要高度技术力才能玩转的「AI 应用」,由 Intel 和这些 AI 软件厂商们组成的「朋友圈」,实际上才更能推动 AI PC 和 AI 应用在市场中真正的普及,从而为整个 AI 生态带来可持续发展的动力。
来源:互联网


