
在 OpenAI 连续 12 天的技术发布会上, 一项名为 RFT(Reinforcement-based Fine-Tuning, 基于强化学习的微调) 的新型训练方法引发全球关注。该方法通过结合强化学习与监督微调, 仅需少量标注数据即可显著提升模型在特定场景下的性能。2 月 28 日, 百度智能云千帆 ModelBuilder 成为了国内首个全面支持 RFT 训练方法的大模型开发平台, 为企业开发者提供更高效、低成本的大模型开发模式, 进一步降低生成式 AI 应用落地的门槛。
在 OpenAI 连续 12 天的技术发布会上, 一项名为 RFT(Reinforcement-based Fine-Tuning, 基于强化学习的微调) 的新型训练方法引发全球关注。该方法通过结合强化学习与监督微调, 仅需少量标注数据即可显著提升模型在特定场景下的性能。2 月 28 日, 百度智能云千帆 ModelBuilder 成为了国内首个全面支持 RFT 训练方法的大模型开发平台, 为企业开发者提供更高效、低成本的大模型开发模式, 进一步降低生成式 AI 应用落地的门槛。
什么是 RFT:大模型高效训练的新范式
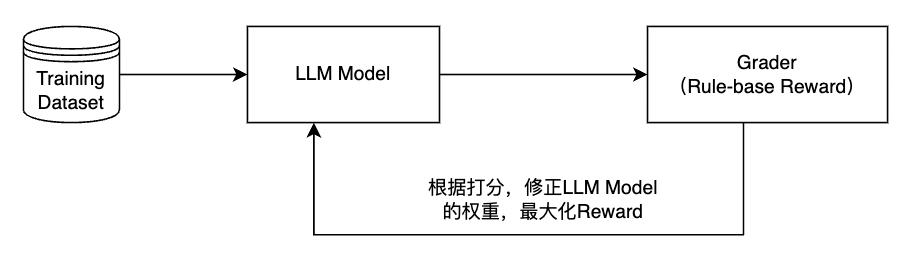
RFT 融合了强化学习 (RL) 和微调 (Fine-tuning) 技术, 突破了传统训练依赖大量人工标注偏好数据的局限, 借助 Grader 比较模型 Response 和 Reference 进行打分 (0 - 1), 自动分配奖励信号, 驱动模型优化。
这一训练方式的优势在于,AI 可以自己思考, 强化导致正确答案的思维路径、抑制导致错误的思维路径, 可以在用户的少量专业数据中完成推理, 从而完成强化学习, 迅速达到细分领域的专家水平。
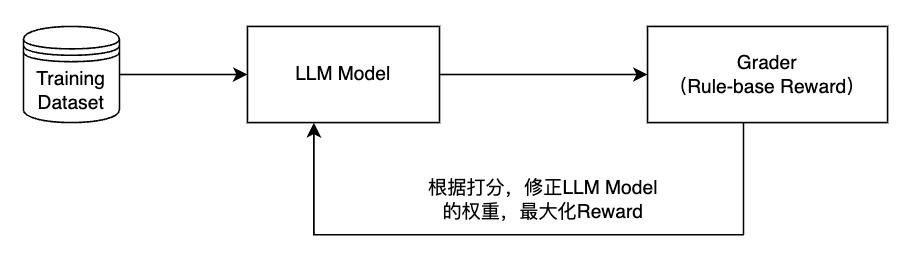
RFT 融合强化学习 (RL) 与监督微调 (SFT), 通过以下机制突破传统训练瓶颈:
1、 奖励信号自动化引入Grader 模块(基于规则或参考答案的评分器), 对比模型输出与参考答案 (Reference), 自动生成 0-1 分值的量化奖励信号, 替代人工偏好标注。
2、 策略优化智能化基于PPO 算法构建强化学习框架, 驱动模型通过自主探索优化输出策略, 避免传统 SFT 的局部最优局限。
千帆 ModelBuilder RFT 训练全流程解析:RFT 如何让模型实现"思维跃迁"
在千帆 ModelBuilder 的实测中,RFT 展现出"超强增效"特性:
数据效率:复杂场景下, 仅需 4500 条训练数据即可完成训练, 并保证模型效果。
泛化能力:在 3-8 人复杂度递增的"好人/坏人"推理场景中, 平均准确率相比 base 模型提升 29%。
训练天花板:在复杂问题场景下,RFT 的训练能力天花板更高。
千帆 ModelBuilder 上的 RFT 训练三步曲
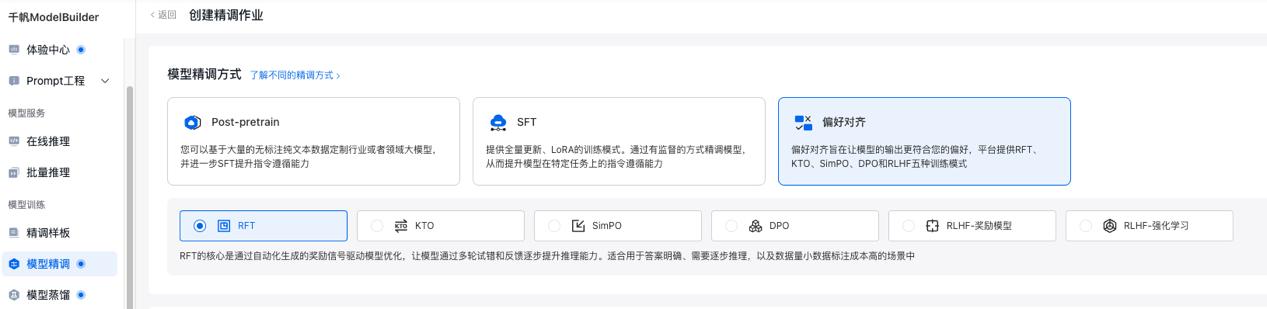
Step 1:创建 RFT 训练任务
在千帆 ModelBuilder 上, 选择「模型精调」→「偏好对齐」→「RFT」, 并选择 base 模型 DeepSeek-R1-Distill-Qwen-7B, 同时配置奖励规则 (平台预置四种规则, 奖励规则中定义了如何评估模型输出效果的规则)。
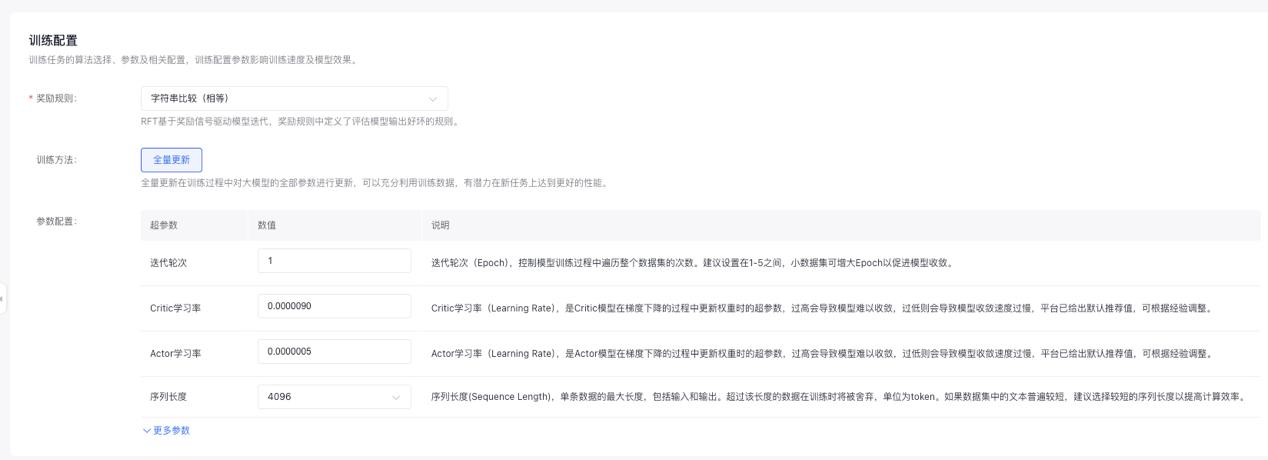
Step 2:准备训练数据
采用开源数据集 K-and-K/knights-and-knaves(约 4,500 条数据);平台数据配置中, 数据格式需包含 Prompt(问题) 与 Response(参考答案)。

Step 3:模型部署与效果快速评估
配置成功后, 在平台即可一键开启模型训练, 训练完成后一键部署至千帆 ModelBuilder, 同时平台支持创建自动评估任务, 通过 ERNIE-4.0-Turbo 作为裁判员模型并自定义评估指标, 快速得到模型评估结果。
效果验证—RFT「超强增效」:训练后的模型回答准确率大幅提升, 超越 OpenAI o1 模型!
整个训练过程, 基于百度智能云千帆 ModelBuilder 平台, 利用 base 模型 DeepSeek-R1-Distill-Qwen-7B 使用约 4500 条少量数据, 完成 RFT 训练;根据回答准确率以及 case 示例分析, 得出 2 个关键结论。
准确率跃升, 训练天花板更高:在 3-8 人复杂度递增的场景中,RFT 后的 DeepSeek-R1-Distill-Qwen-7B 平均准确率提升 29%, 超越了 OpenAI o1;同时对比 SFT-全量更新后的模型回答准确率, 发现在逻辑推理场景下,RFT 的效果提升更显著, 训练天花板更高。
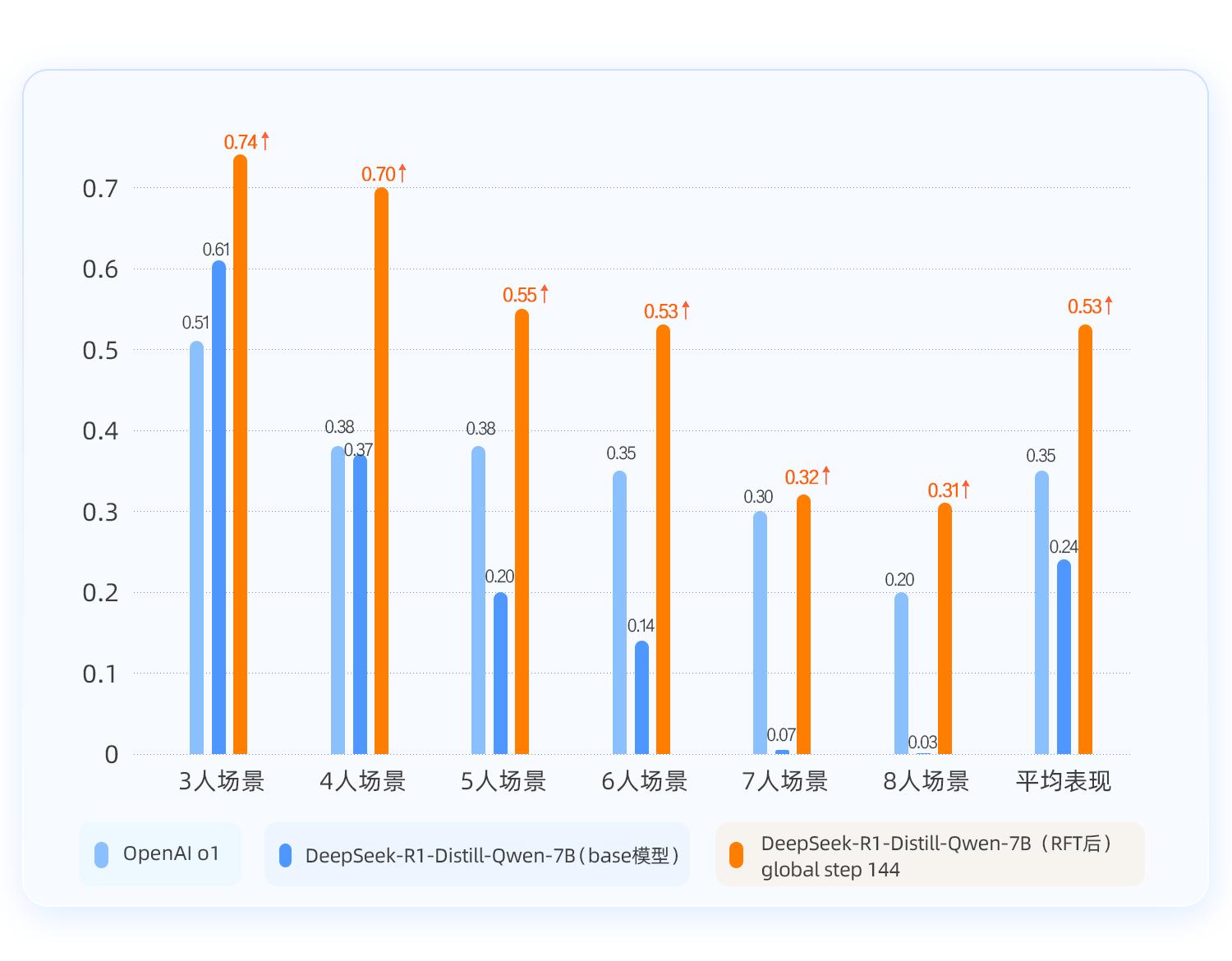
泛化能力增强:RFT 前 Base 模型的输出答案以及思考过程均有明显错误, 并且当题目难度越高的时候甚至模型回答语言已经错乱;而 RFT 后, 模型输出的答案准确, 思考过程也更加清晰。
来源:互联网


