

智谱又完成一笔金额战略融资。
3月3日消息,极客公园获悉,近日智谱完成一笔金额超10亿元人民币的战略融资,参与投资方包括杭州城投产业基金、上城资本等,旨在推动智谱国产基座GLM大模型的技术创新和生态发展。
据了解,智谱已在杭州成立了浙江智谱新篇科技有限公司,依托前沿人工智能和大模型技术,以更好服务浙江省和长三角地区的经济实体。
目前,智谱GLM系列大模型已在金融、医疗、教育等多个行业得到广泛应用,通过智谱与地方国资的深入合作,将有助于以大模型带动全产业链生态智能化发展。
根据公开资料,极客公园整理智谱自2019年成立以来的融资历程如下:
2019年,天使轮融资,投资方包括清华大学计算机系知识工程实验室技术成果转化团队主导,早期支持方包括中科创星、华控汇金等;
2021年9月,A轮融资过亿元人民币,达晨财智、华控基金、将门创投、图灵创投等十余家机构联合投资;
2022年9月,B轮融资数亿元人民币君联资本、启明创投联合领投;2023年全年分多阶段完成B轮系列融资,超25亿元人民币,战略投资方为美团(3亿元B+轮)、社保基金中关村自主创新基金(君联资本管理),跟投方包括蚂蚁集团、阿里、腾讯、小米、红杉、高瓴等;
2024年6月,C轮4亿美元(约28.8亿元人民币),领投方为沙特阿美旗下Prosperity7 Venture,此时估值达到30亿美元(约210亿元人民币);
2024年8月,C+轮融资超10亿元人民币,领投方为君联资本,跟投方包括顺为资本、红杉中国、腾讯等;
2024年12月,D轮融资30亿元人民币,领投方为中关村科学城公司,估值260亿元人民币(约46.15亿美元)。
此前截至2024年底,智谱累计融资超70亿元人民币,在2025年2月最新估值为46.15亿美元(约300亿元人民币)。
有了六小龙的杭州,又盯上六小虎
近年来,已经有六家科技新锐企业在杭州崛起,分别是深度求索(DeepSeek)、宇树科技、游戏科学、云深处科技、强脑科技和群核科技。
这些公司在人工智能、机器人、脑科学等领域取得了显著成就,成为杭州科技创新的代表,并在全球科技圈引发广泛关注。就在周六,DeepSeek公布了运营数据——单日理论成本利润率高达545%,再次震动行业。
杭州拥有完整的AI产业链条,从芯片、算法到应用层,上下游企业协同发展。这种完整的产业生态为“六小龙”的技术创新和商业化提供了坚实基础。
也因此可以看出,杭州国资此次对大模型六小虎之一智谱的青睐,并非偶然。
智谱从 2019 年成立之初,就从清华大学计算机系知识工程实验室技术成果转化而来,此后一路推进:
2021 年提出 GLM 模型算法并发布百亿模型 GLM - 10B,同年训出 MOE 架构的万亿模型悟道;2022 年加大投入,训出国内第一个千亿开源模型 GLM - 130B;2023 年推出线上可用的中国 ChatGPT(ChatGLM),引领中国大模型发展和商业化;2024 年,智谱 GLM 的原创算法得到 Nature 报道,从基座模型能力延展至多模态和 Agent;2025 年,智谱宣布将发布全新大模型并开源,将为国产大模型生态注入新的活力。
作为国内唯一全面对标美国 OpenAI 的大模型企业,智谱 GLM 系列大模型在千亿基座模型、对话模型、代码模型、多模态模型、推理模型和 Agent 等方面布局完整,原创架构全面对标 GPT。
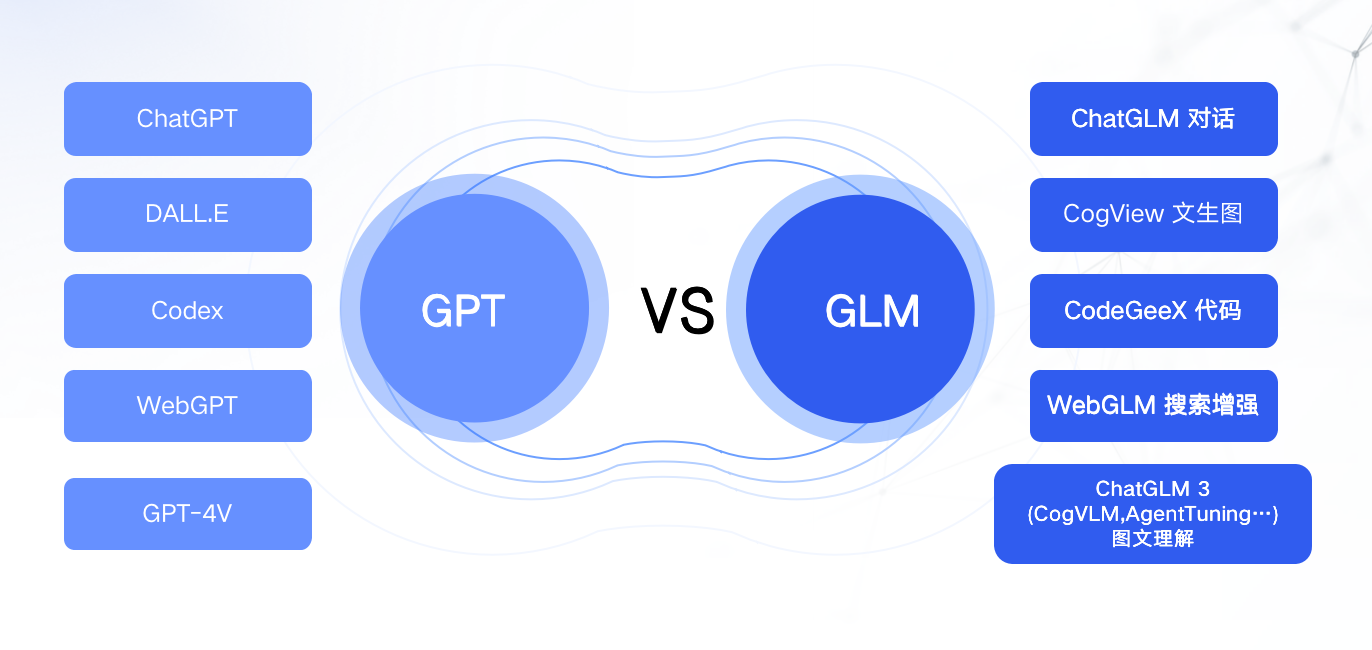
智谱 AI 此前公开的对标 OpenAI 全模型产品线|图片来源:智谱
2024 年下半年,智谱推出的基座模型 GLM - 4 - Plus、Agent 模型 AutoGLM、推理模型 GLM - Zero 等,都展现了比肩 OpenAI 的实力。GLM 预训练架构更是实现了从预训练理论、技术到预训练工具等全方位的全栈自主创新,推动形成了自主的超大规模智能模型技术创新体系。
在技术趋势的把握上,智谱也展现出了洞察力。继长推理模型之后,智谱看到了Agent技术的潜力,先于 OpenAI 提出 Phone Use 概念,推出能模拟用户进行计算机、手机等跨应用自主操作的 AutoGLM 和 GLM - PC,并基于 Agentic GLM 与三星手机展开合作,在国内外大模型中处于领先地位。
2025 年,Agentic LLM 将高效整合物理与数字世界资源,原生支持工具调用和迭代优化,从而提升任务可靠性,实现从被动应答到主动执行的范式转变,推动基座模型能力快速落地于生产力。
在大模型商业化方面,智谱走出了属于自己的路径。在大国博弈和大厂博弈背景下,主权大模型和自主可控大模型的重要性日益凸显,建立安全、无幻觉、自主可控的大模型是行业发展的迫切需求之一。
事实上,智谱自成立以来就在大力推动 GLM 生态繁荣,其大模型适配了国内 40 多种 GPU 芯片,推动进口替代,并在安全性、可控性及幻觉率等关键技术方面取得了突破,成为国内幻觉率最低的大模型之一。
基于系列大模型,智谱构建了 MaaS、私有化部署、智能体平台等服务模式,形成包含百万规模开发者的模型服务新生态,为金融、医疗、教育、政务等 20 多个行业提供服务,在万余家企事业单位实现了规模化应用。
并且,智谱商业化进程并没有被deepseek的热潮所影响到,据了解智谱节后不到一个月收入超过1亿,API平台付费增长超过30%。
智谱在大模型技术领域的创新与突破,契合了杭州AI产业发展的需求;而其技术实力和商业化进展,又能够为杭州的科技生态注入更多动能。
All in AGI,其他都是路径
今年以来,「开源」在业内的重要性再次被重申。
DeepSeek-V3、R1模型的爆火,给到业界各方压力。2月中,OpenAI透露了其尝试了其尝试开源的新动向,此前一直走闭源策略的百度也宣布了文心一言免费、开源,而在本周六,deepseek开源周彩蛋里的「理论利润率545%」,再次震动行业。
作为国内最早开源大模型的人工智能公司,智谱在2022年就开源了自主研发的高精度双语千亿模型 GLM-130B,此后又先后在2023年开源 ChatGLM3-6B 和多模态模型 CogAgent-18B,2024年发布第四代 GLM-4 系列开源模型,包括 GLM-4-9B 等。
作为国内最早开源大模型的企业,智谱在开源领域的贡献,也是它赢得了杭州国资青睐的原因之一。
2025年也将是智谱的开源年。据悉智谱很快会发布全新大模型(包括基座模型、推理模型、多模态模型、Agent等)并将其开源。
在DeepSeek 强势冲击 AI 市场后,智谱CEO张鹏在接受媒体采访时称,“将All in AGI,其他的都是路径。而在路径上,智谱AI每天都在优化。”
去年以来,AI六小虎中已经有一些公司选择大幅调整发展方向,而智谱仍在专注于大模型技术创新和追求AGI。
智谱从2019年成立就定下了实现AGI的愿景,将AGI的发展路径分为五级,L1预训练大模型、L2对齐&推理、L3自我学习、L4自我认知、L5意识智能。目前AGI正位于从L2向L3发展的关键阶段。总体趋势是Scaling Law本质未变,模型效果的关键还在于超大规模高质量数据、模型算法和算力的提升。
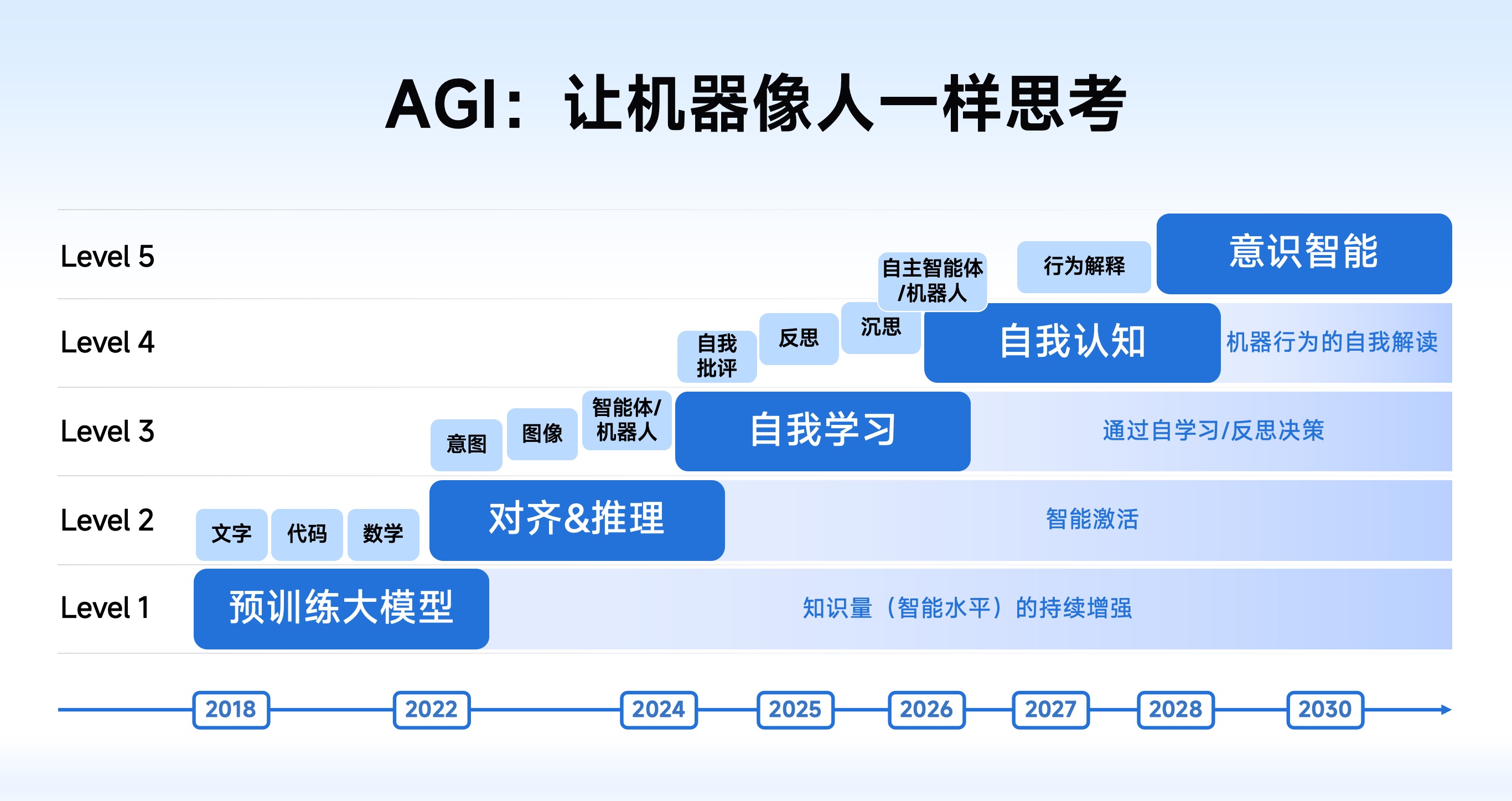
图片来源:智谱
智谱的AGI分级分为:L1 预训练大模型、L2 对齐&推理、L3 自我学习、L4 自我认知、L5 意识智能,具体对 AGI 从 L1-L5 的思考如下:
L1 预训练大模型,即基座模型,其核心作用为提供知识量。
L2 对齐&推理,本质上是“智能激活”,即对齐机器与人类的意图,对齐文本、图像、视频、音频等不同模态。同时教会机器进行像人类一样的推理和规划。
在 L1、L2 阶段,AI 学习知识、推理和规划,依然需要来自人类的教学。但在 L3 自我学习阶段,AI 可以通过自我批评、反思、甚至沉思来实现自我学习。沉思让具备自我学习能力的 AI 可以自主解决开放域问题,即使是从未见过的问题,它们也可以像人类一样通过不断尝试、不断探索来解决。
L4 自我认知阶段,AI 可以对自己的行为/动作作出解释,知道因为什么才得出了这个结果。
L5 意识智能是 AGI 的最后一级,即 AI 在未来某一天会具备某种意识,可以像人一样去突破现有天花板,去探索、研究、寻找科学的新边界。
杭州国资对智谱的战略投资,看起来既是区域AI布局的深化,也是对国产大模型技术自主可控趋势的押注。


