

思维链的出现意味着,大模型未来可能可以通过自我的对抗强化学习,产生新的知识,超越人类知识的边界。
在 OpenAI o1 正式版发布 10 天后,Kimi 的「高阶推理模型」也落地了。
12 月 16 日,Kimi 直接发布了自己的「视觉思考模型」k1。相比于一个月前发布的 k0-math,k1 支持端到端的图像理解和思维链(CoT),不仅推理能力进一步提升,还可以识别几何图形、图表等图像信息。
增强推理之后,大模型会获得更严密的逻辑思考能力,在基础科学领域的能力表现大幅提升。如果说过去的大语言模型相对更接近「文科生」,那么现在,它学会了「数理化」。
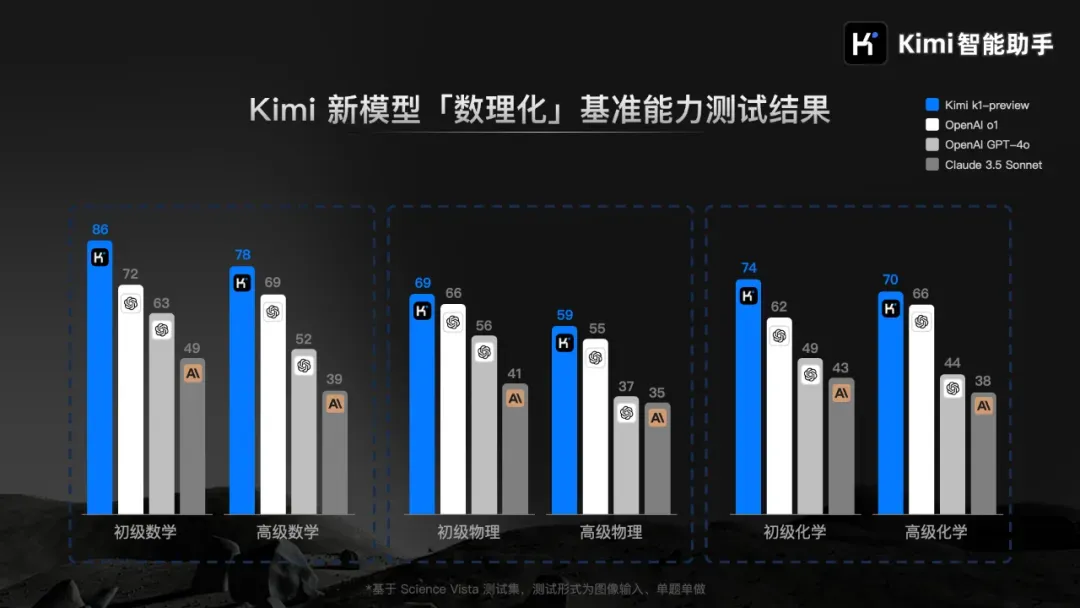
发布模型的同时,月之暗面宣布,Kimi k1 在多项基础学科的基准能力测试中表现优异,超越了 Open AI o1、GPT-4o,及 Claude 3.5 Sonnet。
学会「数理化」,意味着 Kimi 的能力得到了扩增。但更重要的是,高质量「思维链」的出现,将彻底改变大模型的思维深度,让它具备「自主探索答案和反思」的能力。
学会「自主探索和反思」,或许就是 AI 扩宽人类知识边界的关键所在。
01
学会「数理化」的大模型
今年夏天,就有媒体利用高考试卷,测试了大模型的「知识水平」。
得到的结果相当惊人,不少大模型的测试成绩,都达到了「一本线」的水平,但仅限「文科」。大模型最擅长的学科是语文、英语,以及政治历史,这几门课基本都可以拿到 80 分以上,英语更是可以接近满分。但数理化三科,大部分模型都无法及格。包括文综三科里,比较注重逻辑判断的地理,大模型的表现也欠佳。
这里最大的原因在于,大模型缺少「推理」能力,去对输出的内容进行「收敛」。面对那些较为开放,没有唯一标准答案的主观题,大模型往往能引经据典,给出丰富的回答,组织语句的能力也较强——这都是语言模型的「老本行」。但面对那些理科的客观题,只有唯一标准答案的时候,大模型就较难命中靶心。
所以,想要衡量下一代「高阶推理模型」的能力高低,很大程度上,就是要看它的理科成绩如何。
此次 Kimi k1 发布,月之暗面公布的第一项基准测试,就是「数理化」三门学科的能力测试。根据测试结果,k1 大幅领先于 GPT-4o。而 4o 曾是今年夏天在高考测试中表现相对最好的大模型。同时,k1 相比 OpenAI 最先进的高阶推理模型 o1,也存在一定优势。
不只是中学水平的数理化,Kimi k1 对于更高阶的问题也具备相当强的解析能力,比如奥赛数学。我们尝试输入了一道主要面向高校的数学奥赛题目给 Kimi,它也顺利完成了推理解答,并得到了正确答案。
如果说,此前通用大模型 AI 的知识水平大概处于「高考一本线」左右,那具备高阶推理能力的 k1,在一些领域则至少来到了研究生,甚至博士级的水平。

在应用层面,k1 具备两个重要特点,第一是对视觉内容的「端到端」支持,用户只需要输入问题截图、拍照,甚至是手写的题目,Kimi 都能够识别出原题,并进行推理解答。即便画面里有噪声,不够清晰,也没有问题。特别是针对那些有图示的几何题、应用题,Kimi k1 能够结合图示来理解题意,这是过去的大模型很难做到的。
其次,则在于 Kimi 具备「思维链」技术,让用户看到的不只是答题结果,而是能看到模型思考和推演答案的全过程。
到这里,看起来 k1 最主要的应用价值是教育,能成为学生和家长的「辅导助手」,但事情远没有这么简单。
02
会「一步步思考」的 AI
当我们尝试用 Kimi k1 来解答一系列中学数理化问题,会发现明显的特征是,k1 的思考过程非常细,甚至有时候会有点「太细了」。
它会把一个问题分析、拆解到最底层,产生结论之后,还会主动从其他角度进行二次思考,来验证自己之前的想法是否正确,如果发现矛盾,就会进行进一步的反思。
思维链究竟应该细化到何种程度,目前还没有一个全行业共识的答案。但可以肯定的是,大模型的思维链能力可以启发人类做事的思路。这是许多行业的专业人士在使用推理模型后,最常发出的感慨。
目前这一代「高阶推理模型」所具备的思维能力,率先在数理化解题、专业知识解读等场景下,得到了最明确的体现。而这种推理能力更深层的意义,在于「反思」。
「反思」能力的出现,通过思维链技术,能让大模型输出的内容变得更有逻辑,更可控且灵活。
当下大模型应用场景里,明显存在的一个矛盾是:当我们提出一个问题,如果我们自己不知道答案,我们就依然无法判断大模型给出的答案是否正确。
但如果大模型能给出自己的逻辑思维过程,我们就可以参考这个过程,来判断答案的合理与否。所以当下包括 Kimi k1 在内的模型,一个最好用的 prompt 就是「一步步分析」,这样经过专门训练的大模型就能给出更详细的思考过程,供用户进行参考评估。

这有助于消除大模型的「幻觉」问题。就是说,大模型可以自己对自己的拟合结果进行反思,尝试把那些可能错误的内容剔除出去。即便生成结果中包含一些可疑的、不确定的部分,用户也更容易从 AI 的思考过程中发现这些内容,进行二次审核确认。这对 AI 的安全性、可靠性,也会是一个积极提升。特别是对专业领域的用户来说,这一点将非常有意义。
通过「思维链」,Kimi k1 不仅能进行更复杂的思考,对输出结果进行收敛,还能输出更有逻辑的结果,弥合与用户之间的认知鸿沟。
03
用「反思」突破人类知识边界
高阶推理能力、思维链、端到端的视觉输入……大模型 AI 正在经历一轮新的颠覆性改变。Kimi 再次占据了优势身位。
过去大模型所采取的,泛意义上的机器学习思路,更多是基于数据进行「拟合」,也就是模仿。上一代语言模型主要模仿的,就是人类说话、写字的方式。因为 AI 的学习效率很高,通过整合大量的知识数据,就能输出很好的结果。
但这依然注定了,这样的模型只能无限接近人类的水平,而很难超越人类已知的知识范畴,无法产生新的知识。
这也是为什么过去很多人觉得,大模型应用有点像是「什么都懂一点的大学生」,但在任何一个垂直领域都不够深入,无法给出更有价值的独到洞见。
但「反思」能力的出现,则意味着,AI 大模型未来可能可以通过自我的对抗强化学习,产生新的知识,真正超越人类现有的知识边界。
这件事早有成功范例。比如 AlphaGo,就是利用强化学习的方法,基于人类围棋棋手的棋谱,发散出了更多,远超人类棋手所知的策略。之后的 AlphaZero,则是在完全没有输入任何棋谱数据的前提下,只是输入规则,完全通过自我的对抗强化训练,产生了超越人类的智能。
在 Kimi k1 的功能演示中,月之暗面特意输入了一些古代科学家的手稿,这些手稿在今天看起来无比模糊,普通人几乎不可能理解其含义,但 Kimi 也能够通过思考,发掘出很多画面上没有的背景信息。
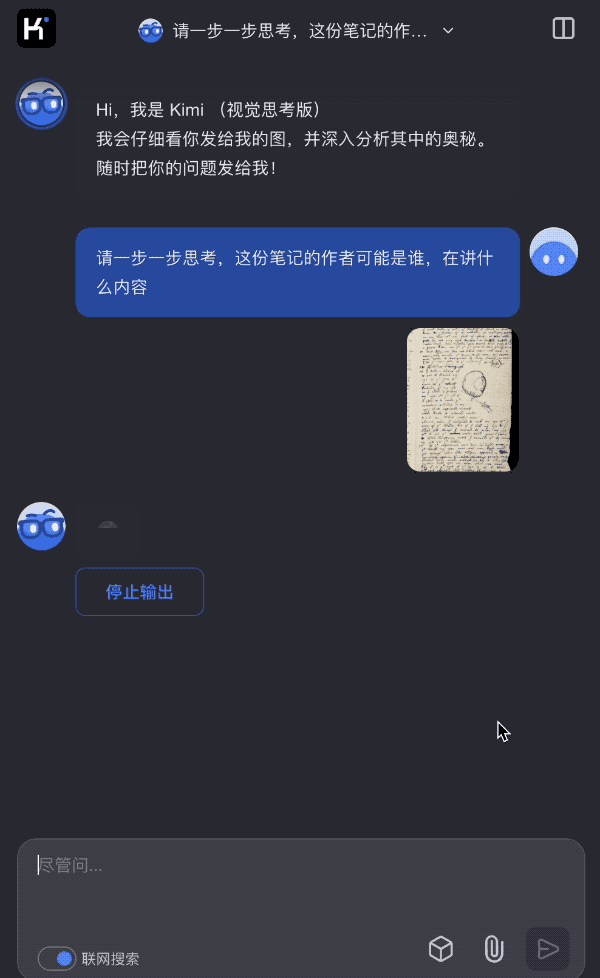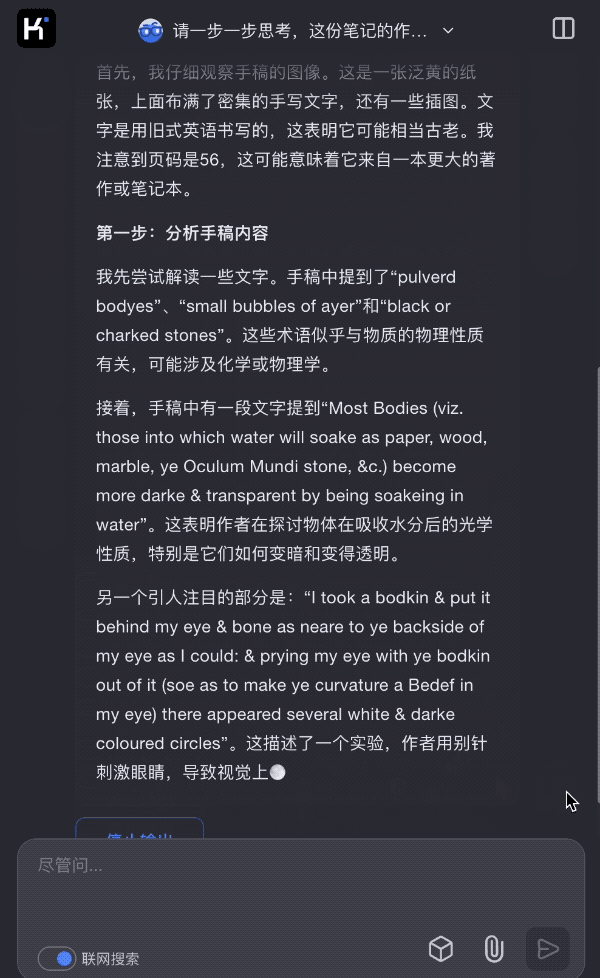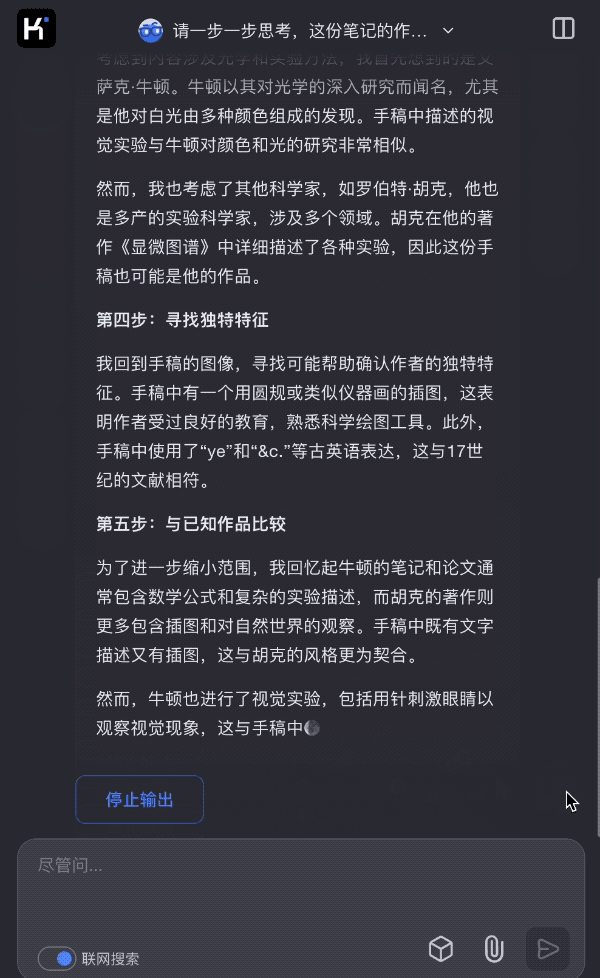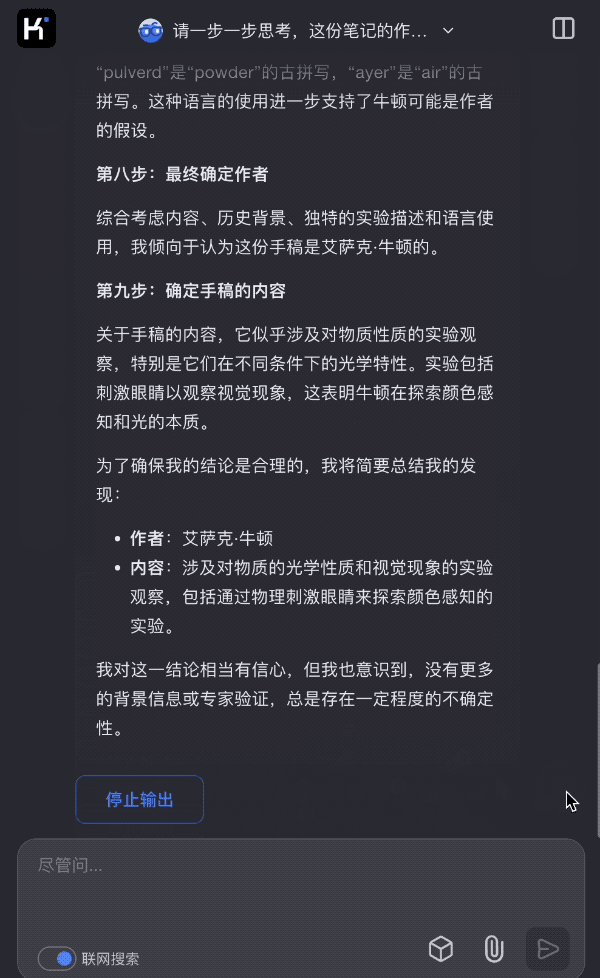
此前曾有一种观点认为:当下人类知识的总量已经太大,人类作为个体,光是学习一个领域的知识,就已经要耗费大量时间,终其一生,可能也很难达到「知识圈」的边界,所以很难像过去的群星闪耀的科学时代一样,不断有惊世骇俗的研究成果出来。甚至有人认为,人类知识的总和,最终会是有限的。
而现在,具备深度思考能力,学习效率超高且具备无穷寿命的 AI,或许正在开创知识和智能的新维度。


