

司南 OpenCompass 评测榜首个开源模型冠军!阿里通义 Qwen2.5 力压 Claude 3.5、GPT-4o 等闭源模型
10 月 17 日记者获悉,司南 OpenCompass 大语言模型评测榜 9 月榜单公布,阿里通义千问开源模型 Qwen2.5-72B-Instruct 击败 Claude 3.5、GPT-4o 等闭源模型,成为该评测榜首个开源模型冠军。据了解,9 月底通义千问开源模型 Qwen 系列的衍生模型数量首次超越 Llama,成为全球最大的开源模型群。
司南 OpenCompass 是由上海人工智能实验室研发的大模型评测体系平台,OpenAI、阿里巴巴、智谱 AI、Meta、零一万物等百余个最主流的大模型均已加入评测,是最具国际影响力的中国权威第三方评测榜单。司南 OpenCompass 自建评测榜单每月一更,从语言、推理、知识、代码、数学、指令跟随、智能体等七大能力维度、十余项细分任务,对近期主流模型进行全面评测分析。
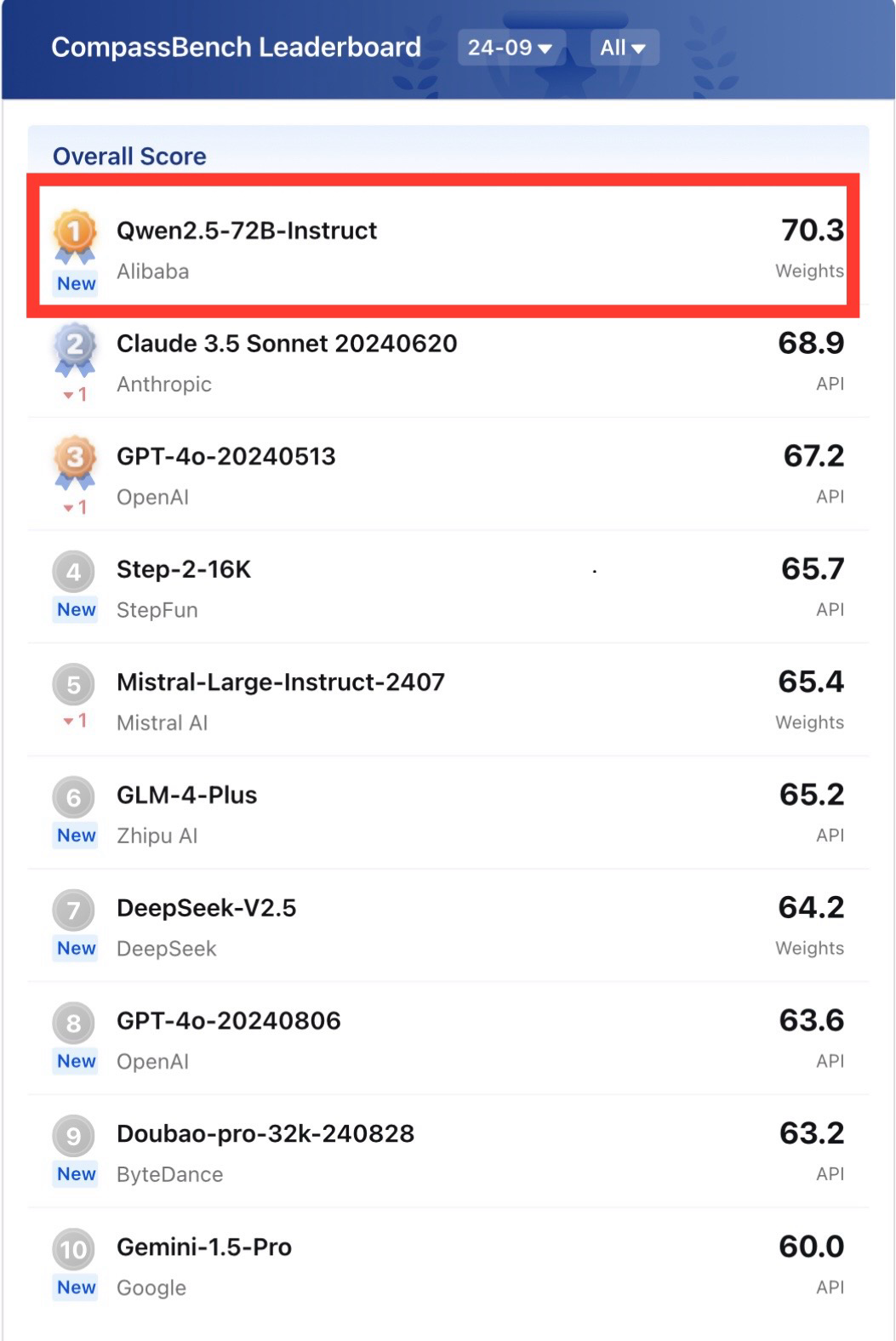
在 2024 年 9 月的司南 OpenCompass 榜单中,开源的 Qwen2.5-72B 以 70.3 分夺冠,首次超越 Claude 3.5 和 GPT-4o 等顶尖闭源模型。Qwen2.5-72B-Instruct 在此次榜单的多项能力测评中均名列前茅。在代码能力方面,Qwen2.5-72B-Instruct 以 74.2 分夺冠,不仅能准确完成代码编写,还能详细解释代码的功能和逻辑;在数学能力方面,Claude 3.5 得分 72.1,GPT-4o 得分 70.6,远不及 Qwen2.5-72B-Instruct 获得的 77 分成绩。
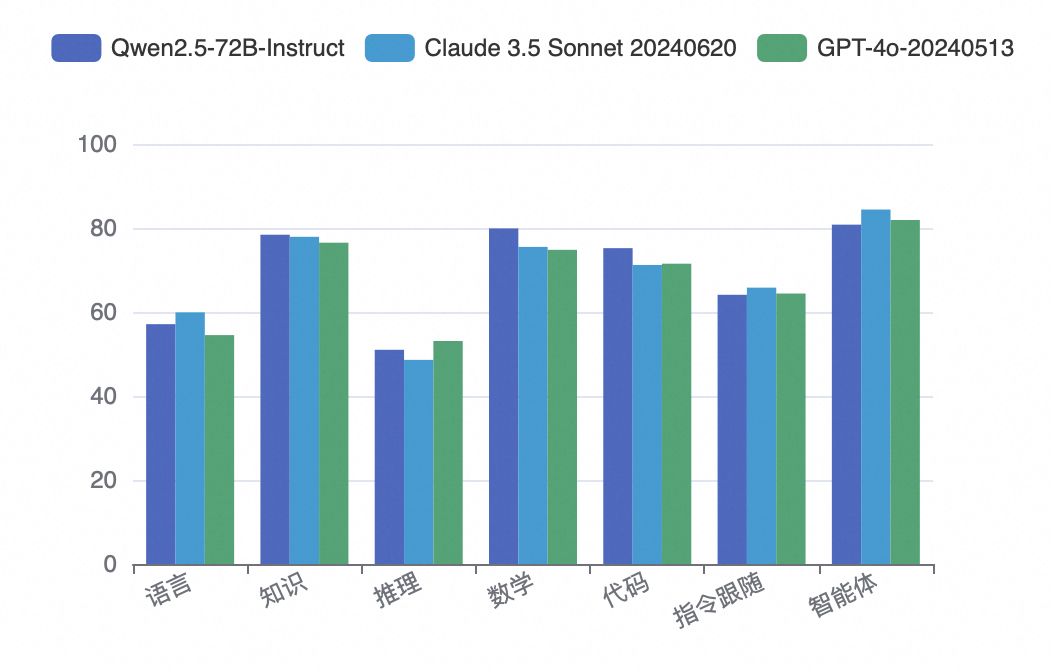
司南 OpenCompass 评价称,Qwen2.5 的登顶,标志着开源社区在模型领域取得快速进展,以 Qwen 2.5 等为代表的国产主流厂商模型,在经历最新一轮技术迭代后,其性能有了显著提升,与国际顶尖模型之间的差距正在快速缩小,展现了国产模型的强大竞争力。
早在 9 月底,Qwen2.5-72B-Instruct 就冲进 Chatbot Arena 大模型盲测榜单前十,是前十中唯一的中国大模型。Qwen 系列开原模型涵盖多尺寸的大语言模型、多模态模型、数学模型和代码模型,几乎所有尺寸的模型都实现了同等规模的最佳性能。截至 9 月底,全球开发者基于 Qwen 系列二次开发的衍生模型数量也已突破 7.43 万,超越 Llama 的 7.28 万,成为全球最大的开源模型群。


