

9 月 19 日云栖大会,阿里云 CTO 周靖人发布通义千问新一代开源模型 Qwen2.5,旗舰模型 Qwen2.5-72B 性能超越 Llama 405B,再登全球开源大模型王座。Qwen2.5 全系列涵盖多个尺寸的大语言模型、多模态模型、数学模型和代码模型,每个尺寸都有基础版本、指令跟随版本、量化版本,总计上架 100 多个模型,刷新业界纪录。
Qwen2.5 全系列模型都在 18T tokens 数据上进行预训练,相比 Qwen2,整体性能提升 18% 以上,拥有更多的知识、更强的编程和数学能力。Qwen2.5-72B 模型在 MMLU-rudex 基准(考察通用知识)、MBPP 基准(考察代码能力)和 MATH 基准(考察数学能力)的得分高达 86.8、88.2、83.1。
Qwen2.5 支持高达 128K 的上下文长度,可生成最多 8K 内容。模型拥有强大的多语言能力,支持中文、英文、法文、西班牙文、俄文、日文、越南文、阿拉伯文等 29 种以上语言。模型能够丝滑响应多样化的系统提示,实现角色扮演和聊天机器人等任务。在指令跟随、理解结构化数据(如表格)、生成结构化输出(尤其是 JSON)等方面 Qwen2.5 都进步明显。
语言模型方面,Qwen2.5 开源了 7 个尺寸,0.5B、1.5B、3B、7B、14B、32B、72B,它们在同等参数赛道都创造了业界最佳成绩,型号设定充分考虑下游场景的不同需求,3B 是适配手机等端侧设备的黄金尺寸;32B 是最受开发者期待的「性价比之王」,可在性能和功耗之间获得最佳平衡,Qwen2.5-32B 的整体表现超越了 Qwen2-72B。
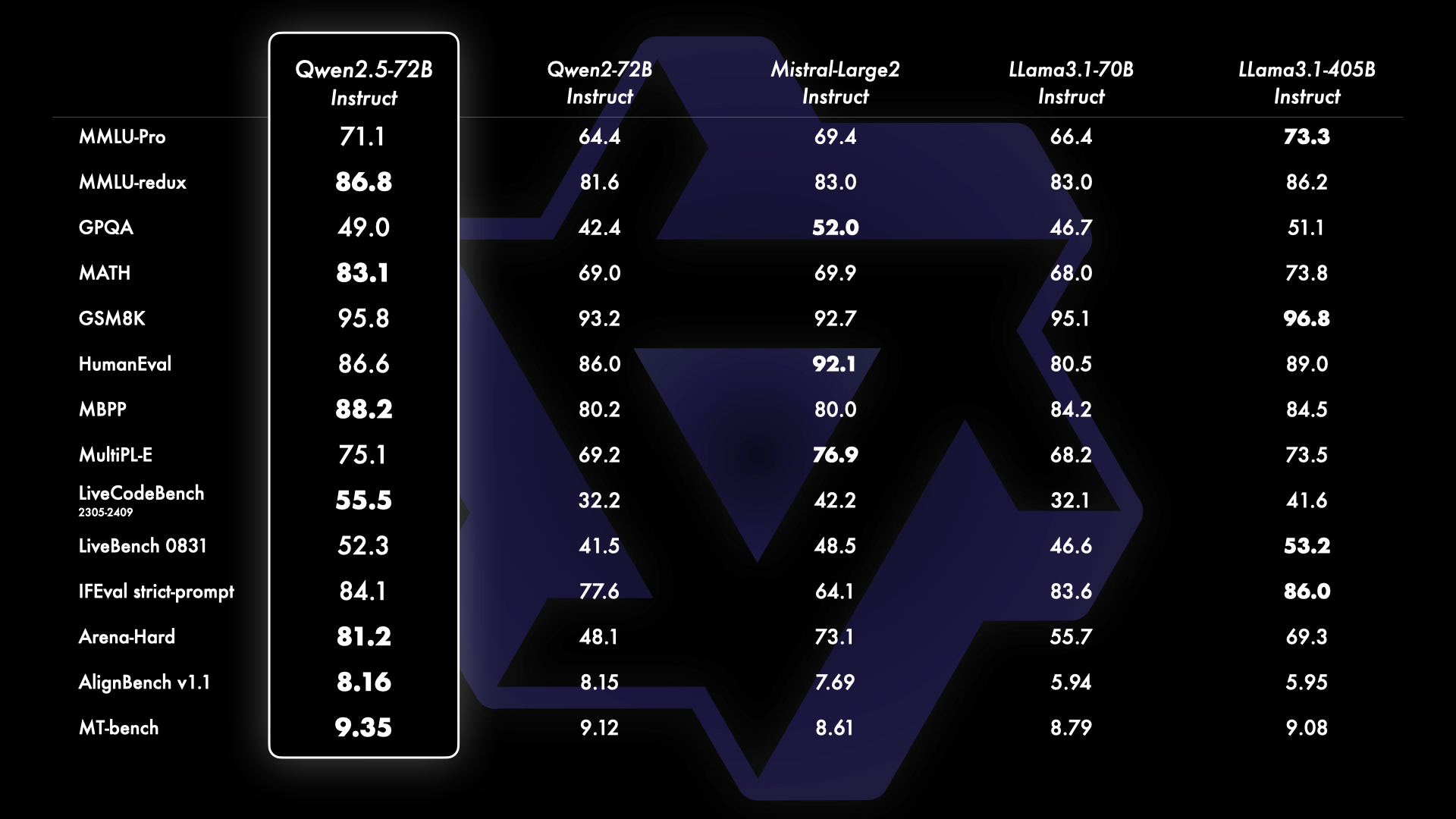
在 MMLU-redux 等十多个基准测评中,Qwen2.5-72B 表现超越 Llama3.1-405B
72B 是 Qwen2.5 系列的旗舰模型,其指令跟随版本 Qwen2.5-72B-Instruct 在 MMLU-redux、MATH、MBPP、LiveCodeBench、Arena-Hard、AlignBench、MT-Bench、MultiPL-E 等权威测评中表现出色,在多个核心任务上,以不到 1/5 的参数超越了拥有 4050 亿巨量参数的 Llama3.1-405B,继续稳居「全球最强开源大模型」的位置。
专项模型方面,用于编程的 Qwen2.5-Coder 和用于数学的 Qwen2.5-Math 都比前代有了实质性进步。Qwen2.5-Coder 在多达 5.5T tokens 的编程相关数据上作了训练,当天开源 1.5B 和 7B 版本,未来还将开源 32B 版本;Qwen2.5-Math 支持使用思维链和工具集成推理(TIR)解决中英双语的数学题,是迄今为止最先进的开源数学模型系列,本次开源了 1.5B、7B、72B 三个尺寸和一款数学奖励模型 Qwen2.5-Math-RM。
多模态模型方面,广受期待的视觉语言模型 Qwen2-VL-72B 正式开源,Qwen2-VL 能识别不同分辨率和长宽比的图片,理解 20 分钟以上长视频,具备自主操作手机和机器人的视觉智能体能力。日前权威测评 LMSYS Chatbot Arena Leaderboard 发布最新一期的视觉模型性能测评结果,Qwen2-VL-72B 成为全球得分最高的开源模型。
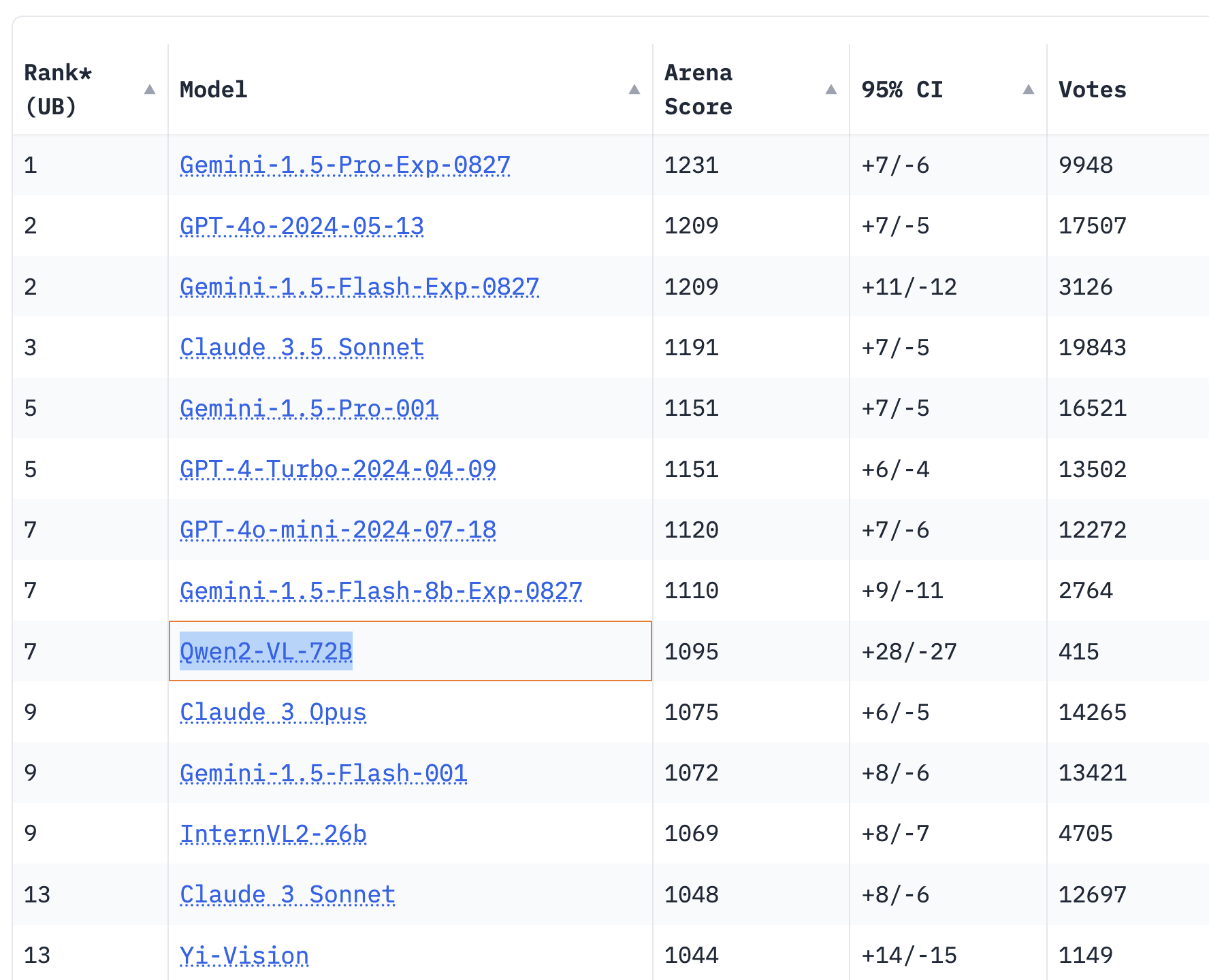
Qwen2-VL-72B 在权威测评 LMSYS Chatbot Arena Leaderboard 成为成为全球得分最高的开源视觉理解模型
自从 2023 年 8 月开源以来,通义在全球开源大模型领域后来居上,成为开发者尤其是中国开发者的首选模型。性能上,通义大模型日拱一卒,逐步赶超美国最强开源模型 Llama,多次登顶 Hugging Face 全球大模型榜单;生态上,通义从零起步、开疆拓土,与海内外的开源社区、生态伙伴、开发者共建生态网络,截至 2024 年 9 月中旬,通义千问开源模型下载量突破 4000 万,Qwen 系列衍生模型总数超过 5 万个,成为仅次于 Llama 的世界级模型群。
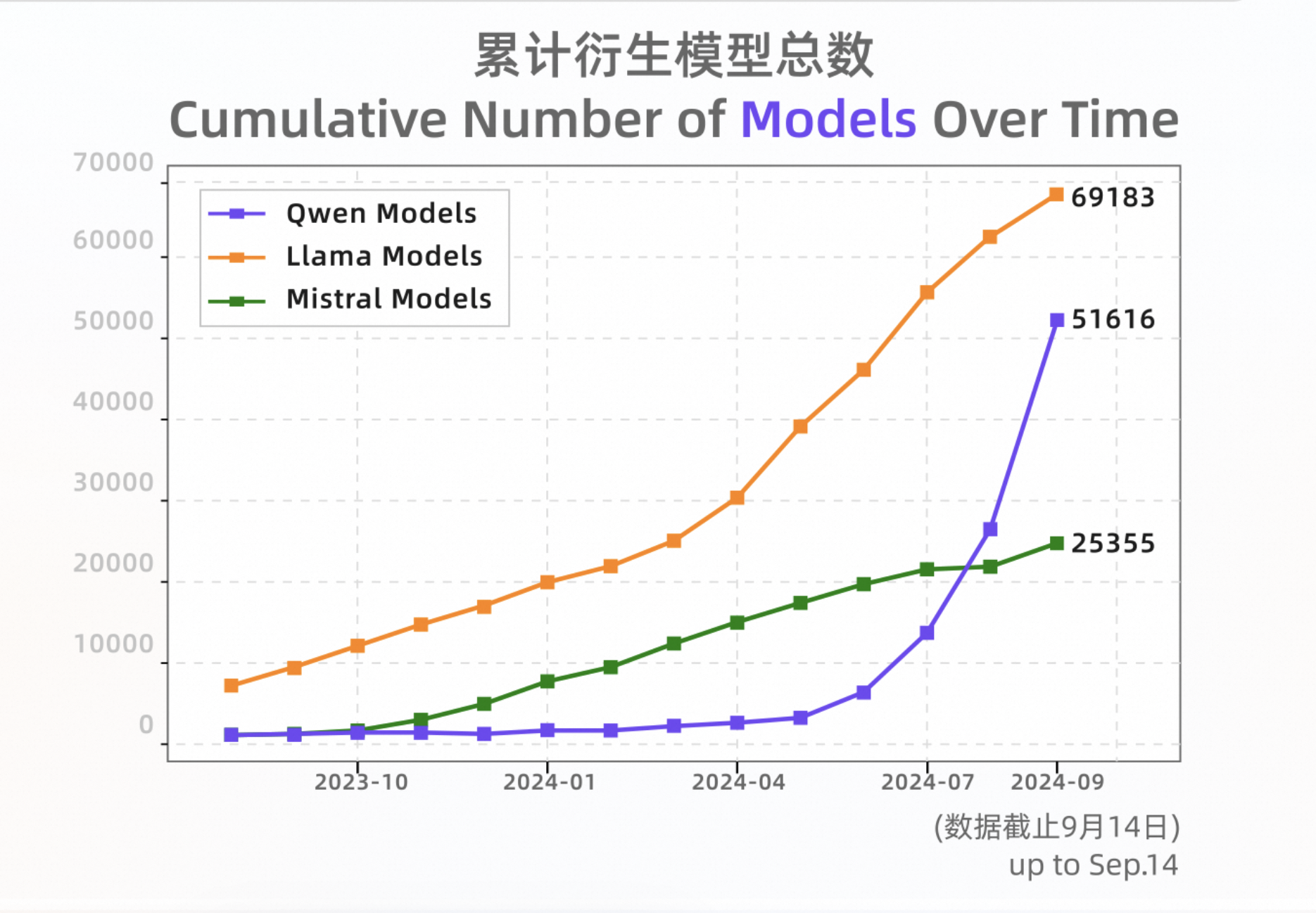
HuggingFace 数据显示,截至 9 月中旬 Qwen 系列原生模型和衍生模型总数超过 5 万个


