

近年来,大语言模型(LLM)问答系统在技术、性能和应用方面得到了长足进步,垂直领域应用已成为 LLM 问答系统落地的主要场景。
近年来,大语言模型(LLM)问答系统在技术、性能和应用方面得到了长足进步,垂直领域应用已成为 LLM 问答系统落地的主要场景。大语言模型 (LLM) 通常基于互联网公开数据训练而成,落地垂直领域应用时需要引入领域知识来增强 LLM 问答系统的准确性和可靠性。一直以来,RAG(Retrieval-Augmented Generation,检索增强生成)技术是这方面的默认选择。直到最近,微软发布并开源了 GraphRAG(图检索增强生成) 技术,一种新的选择成为可能。零点有数将用一文带大家读懂 GraphRAG。
一、LLM 问答系统的不足
尽管大语言模型(LLM)问答系统在技术、性能和应用方面取得了长足进步,但在落地垂直领域应用方面始终存在「致命伤」:存在幻觉——「一本正经的胡说八道」,即生成与事实不符的答案(Response)(简称「事实性错误」)。
附图 1 LLM 问答系统示意图
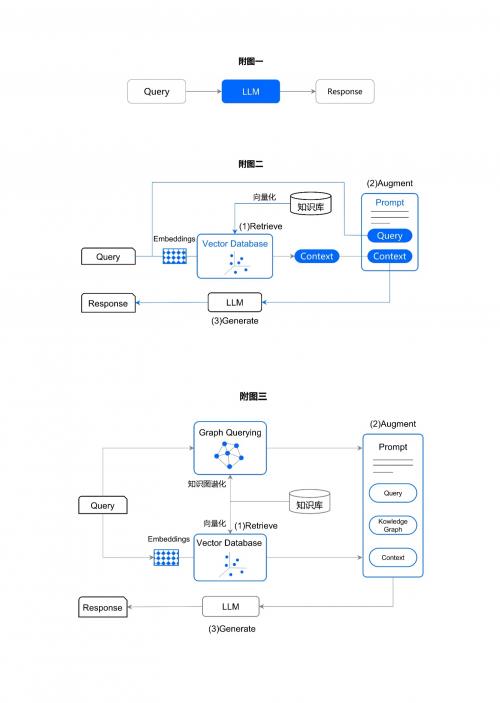
为此,增强 LLM 问答系统在垂直领域方面的知识,以增强答案生成的事实性,减少幻觉,便成了自然的选择——RAG(Retrieval-Augmented Generation,检索增强生成)应运而生。
二、什么是 RAG
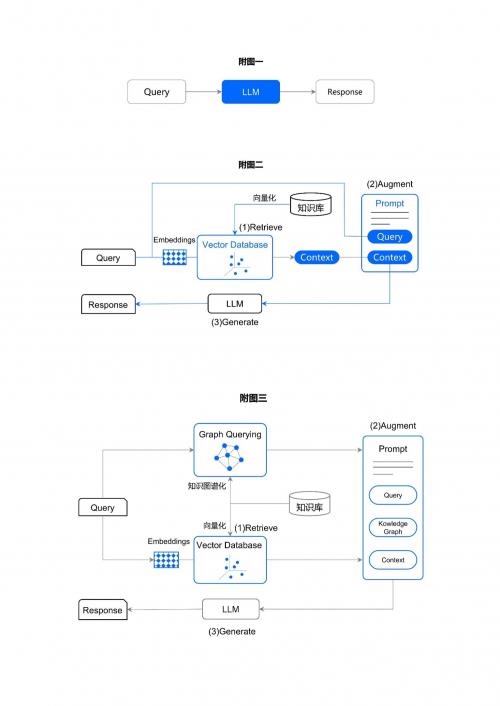
如附图二所示,给定一个查询(Query),RAG 从一个垂直领域知识库(图中向量化后的「Vector Database」)中检索(Retrieve)与查询内容相关的文档或段落(Context,简称「上下文」),并将查询信息(Query)与检索到的上下文信息 (Context) 进行组合转化成 LLM 的「提示词」((Prompt),由 LLM 生成 (Generate) 答案(Response)。这便于 RAG 的应用原理。
相比附图一的 LLM 问答系统由单一的「查询」(Query)形成的「提示词」而言,RAG 的「提示词」信息得到了「增强」(Augmented)——不仅有查询信息(Query), 还集成了通过查询信息检索到与其最相关的上下文(Context)信息。鉴于上下文信息来自于领域知识库(即事实数据),而且是从知识库中检索到的与查询信息高度相关的文档或段落,这使得 LLM 生成的回答(Response)不仅具有较高的准确性,同时还具有较强的事实性。亦即 RAG 不仅可以减少幻觉而且还提高了 LLM 生成答案的准确性。
附图 2 RAG 示意图
虽然 RAG 可以通过将生成的回答与真实数据相关联来减少幻觉,然而对于较为复杂的信息,由于其「检索」能力的局限性而往往导致回答的准确性不尽人意。RAG 检索能力的局限性主要体现在情境理解方面。RAG 模型只能检索 (Retrieve) 到数据集中明显包含有与查询(Query)信息相关的文档或段落,而对于一些不太明显的隐性关系,RAG 往往无能为力。例如,对于一些非结构化文本数据, 尽管客观上是存在与查询信息相关的一些信息的,但由于这些信息显现程度不够,RGA 要么是给出很粗糙的答案,要么是直接「无法回答」。
为此,GraphRAG(图检索增强生成)粉墨登场。
三、什么是 GraphRAG
2024 年 4 月,微软推出 GraphRAG,并于 7 月 2 日开源。GraphRAG 仍然沿袭了 RAG 的思路,即通过检索来增强模型的准确性。不过,与 RAG 不同的是,GraphRAG 还引入了「知识图谱」(Knowledge Graph)技术,以增强模型的「检索」能力,以实现对复杂信息的高效和可靠检索,从而提高 LLM 问答系统对于复杂信息的答案生成的准确性。
对于类似非结构化文本等复杂信息,挖掘其中的隐性信息关系的方法是「知识图谱」,即将非结构化文本等复杂信息通过实体、关系和属性抽取技术,重新组织成结构化的知识图。这种结构化的格式使得模型能够更好地理解和利用不同信息之间的相互关系, 发现其中隐藏的信息连接。同时,这种结构化的检索使得生成答案在语境上更加丰富和准确。应用过程中,GraphRAG 首先会利用大语言模型(LLM)对领域知识进行知识图谱化,构建可「图查询」(Graph Querying)的知识图谱数据库。更进一步地,GraphRAG 不仅可以将全域知识库分割成多社区模块的知识图谱,还可以构建多层次知识图谱(从下至上信息更加抽象化和「主题化」)。这种多社区模块、多层次知识图谱技术旨在全面充分挖掘知识库中的复杂连接和隐性关系,最终实现对全域范围的各种知识关系在广度和深度上的「连点成线」。
附图 3 GraphRAG 示意图
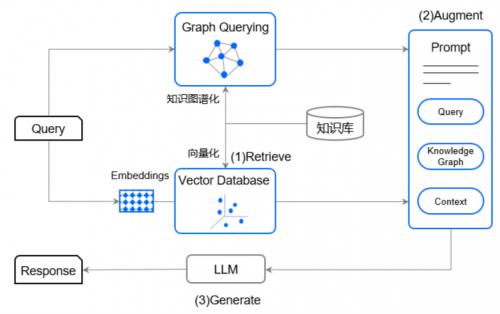
具体检索时,在对知识向量库(Vector Database)进行检索的同时,还将对知识图谱数据库进行检索,并将检索到的知识图谱信息和知识向量信息进行集成转化为「提示词」(Prompt),再由 LLM 生成答案。
与 RAG 相比,GraphRAG 的「提示词」不仅包含有查询信息和根据查询信息检索到的相关上下文信息,而且还集成了从领域知识图谱库中检索到的与查询信息相关的「知识图谱」(Knowledge Graph)信息(在广度和深度上与查询信息相关的各实体、各属性、各关系等信息),更加丰富了「提示词」内容。因而, GraphRAG 不仅能进一步提升 LLM 生成答案的准确性和可靠性,更为突出的是通过知识图谱技术显著地提升了模型的「检索」能力,从而提升了 LLM 问答系统对于复杂信息的处理能力。换句话说,对于复杂信息领域,GraphRAG 弥补了 RAG 的不足。
为了验证 GraphRAG 的有效性,微软研究院基于较为复杂的暴力事件数据集 (VIINA)(未曾用于 LLM 模型训练),选取其中 2023 年 6 月来自俄罗斯和乌克兰新闻的数千篇文章(译成英文)创建了一个数据集(即领域知识库)(如下附图四所示),进行 RAG 和 GraphRAG 检索比对。
附图 4 VIINA 部分数据集

在查询「Novorossiya做了什么?」时,RAG 无法回答这个问题——查看插入上下文窗口的源文档,没有任何文本片段讨论「Novorossiya」,因而导致 RAG 回答失败。相较之下,GraphRAG 通过查询语句中的实体「Novorossiya」,让 LLM 以此为基础建立图谱,并连接原始支持文本从而生成包含出处的优质答案(参见附表一)。
附图 5 RAG 和 GraphRAG 检索比较

附图五中展示了 LLM 在生成语句时所截取的内容,「Novorossiya 与摧毁自动取款机的计划有所关联」。可以从原始文本的片段中看出,LLM 是通过图谱中两个实体之间的关系,断言 Novorossiya 将某一银行作为目标的。
附图 6 原始文本知识图谱生成示意图
事实上,由于 GraphRAG 的多社区模块、多层次知识图谱技术能实现对全域知识范围内的各种相关关系的信息在广度和深度上的「连点成线」,因而 GraphRAG 还可以实现跨领域的检索增强生成。当然,前提条件是所跨的领域之间在「知识」上客观存在「连点成线」的可能。
四、结论
在 GraphRAG 中使用结构化知识图谱增强大模型回答复杂查询的能力的同时,通过提供明确定义的关系来减少产生错误答案的机会,从而使其在开发更可靠和智能的对话式问答系统方面更加有效。将非结构化的知识库转化为结构化图谱还使得 GraphRAG 能够从信息中获得更深层次的含义,使语言模型能够在上下文中准确生成适当的回答。
诚然,如同 GraphRAG 的其他好处一样,GraphRAG 也存在着挑战。其中,最主要的挑战来自知识图谱的构建(需要随着专业领域知识的动态变化而动态构建)及其所引致的计算资源的消耗与运维成本的开销。
鉴于 GraphRAG 刚刚开源,是否代表着 LLM 问答系统应用方面的最优技术路径,还有待观察。但无论如何,GraphRAG 朝着更先进和可靠的聊天机器人系统的发展方向向前迈进了一大步。(作者:许正军)
来源:互联网


