

通义千问 7B 开源模型登顶端侧小模型榜单
7 月 10 日消息,中文大模型测评基准 SuperCLUE 发布 2024 上半年报告,披露针对国内外 33 个大模型的综合测评结果。阿里通义千问的开源模型 Qwen2-72B 成为排名第一的中国大模型,也是全球最强的开源模型,SuperCLUE 报告认为通义千问「超过众多国内外闭源模型」,「引领全球的开源生态」。
CLUE(The Chinese Language Understanding Evaluation)是发起于 2019 年的中文语言理解测评基准,致力于开展科学、客观、中立的语言模型评测,SuperCLUE 聚焦于通用大模型的综合性测评。![]()
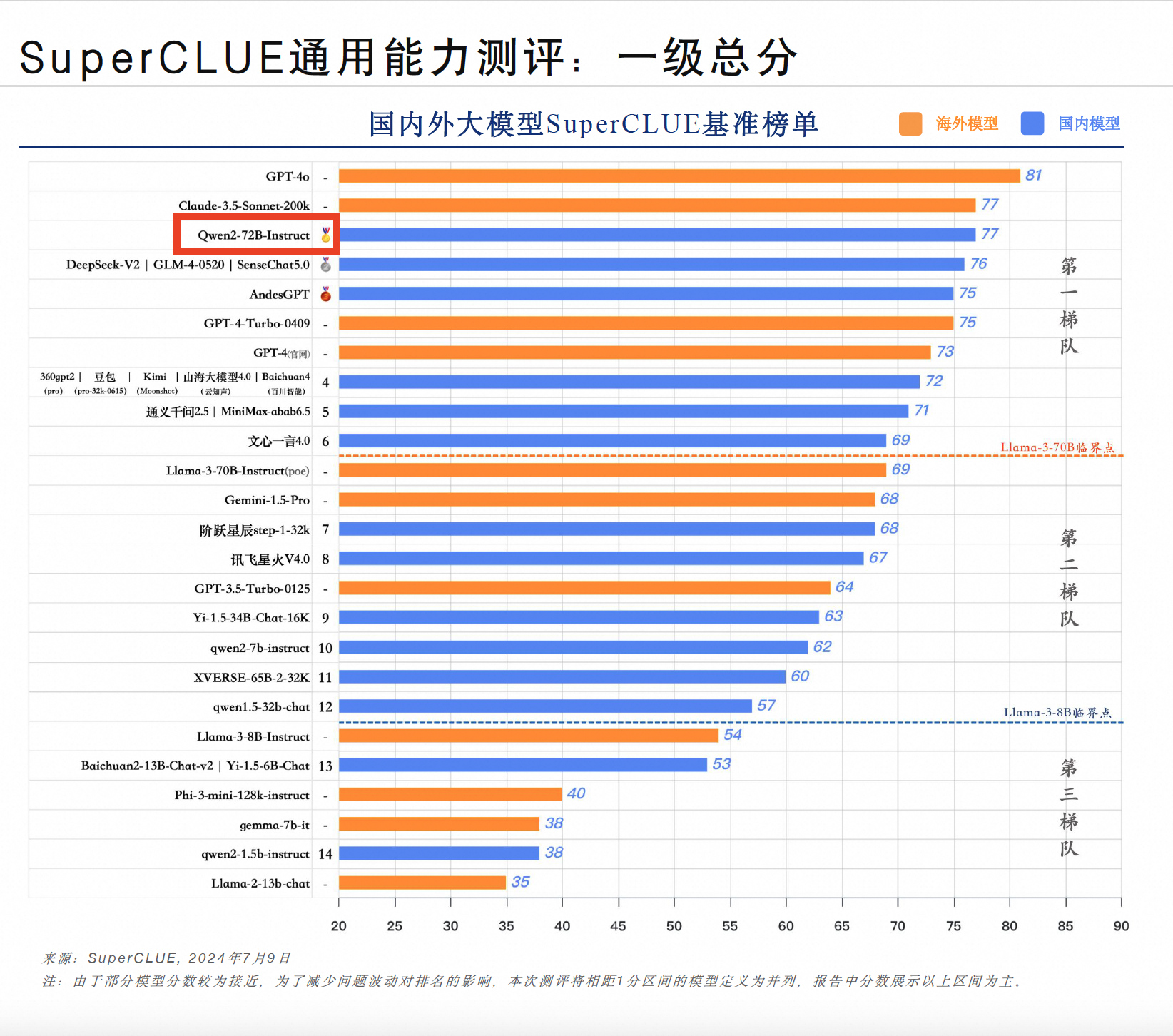
本次半年度测评针对国内外 33 个大模型的 6 月份版本进行,由理科、文科和 Hard 三大维度构成。理科任务包括计算、逻辑推理、代码测评;文科任务分为知识百科、语言理解、长文本、角色扮演、生成与创作、安全和工具使用七大测评;Hard 任务主要是精确指令遵循测评,未来还将推出复杂多步推理和高难度问题解决等测评。
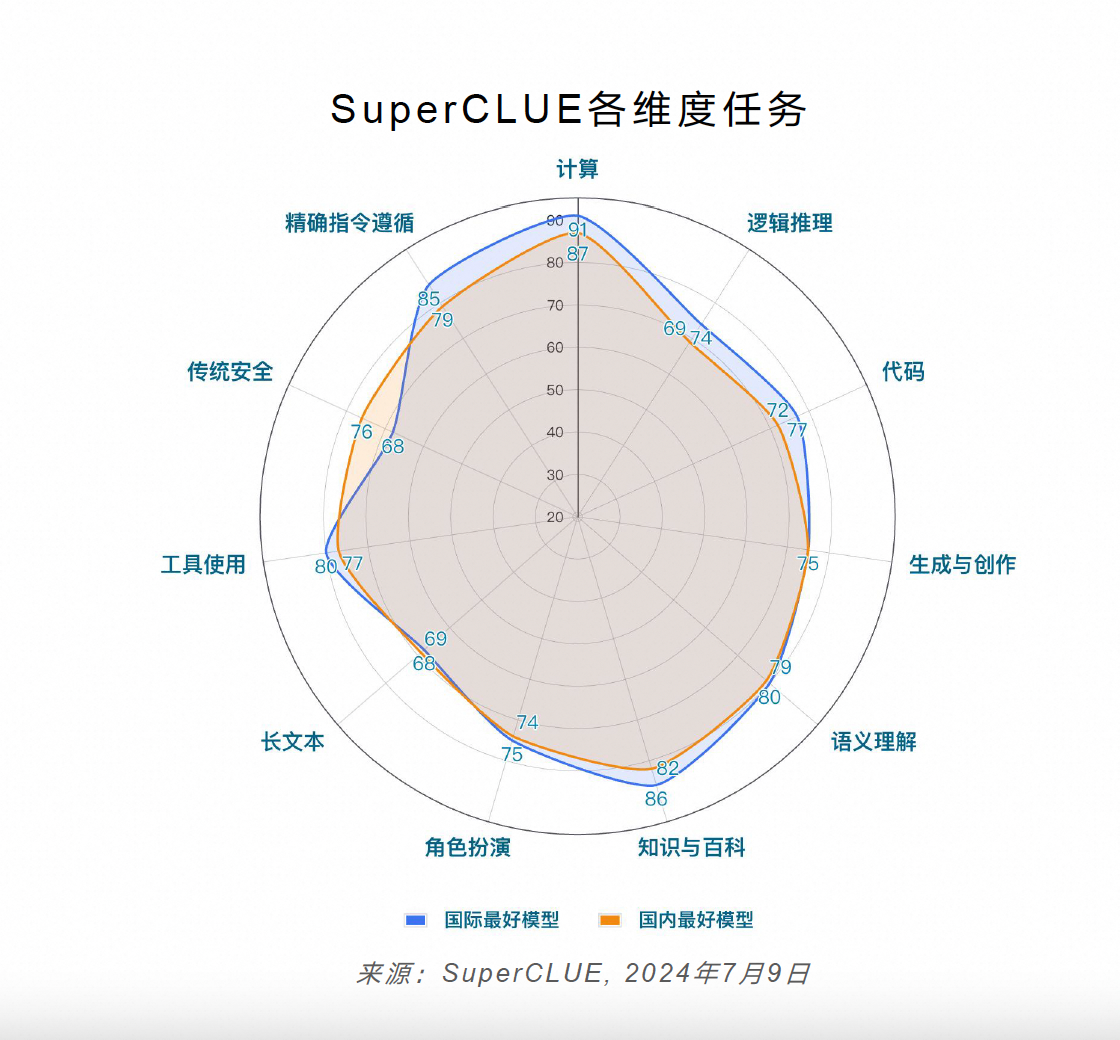
SuperCLUE 国际最好模型(GPT-4o)与国内最好模型(Qwen2-72)的整体性能对比
从代表通用能力的一级总分来看,OpenAI 的 GPT-4o 以 81 分高居榜首,Claude-3.5-Sonnet 与通义千问开源模型 Qwen2-72B-Instruct 并列第二,得分均为 77。通义千问既是排名最高的中国大模型,也是排名最高的开源大模型,性能超越文心一言 4.0、讯飞星火 V4.0、Llama-3-70B 等开闭源大模型。
具体到理科、文科、Hard 三个维度来看,国内外大模型的理科能力存在一定差距,GPT-4o 以绝对优势领跑,Qwen2-72B 的理科测试比 GPT-4o 少 5 分;文科任务上,大模型之间的区分度不明显,GPT-4o 与 Qwen2-72B 等模型的得分均为 76;精确指令遵循能力方面,仅有 GPT-4o 和 Claude 3.5 Sonnet 得分超过 80,国内表现最好的 Qwen2-72B 比 GPT-4o 低 6 分。
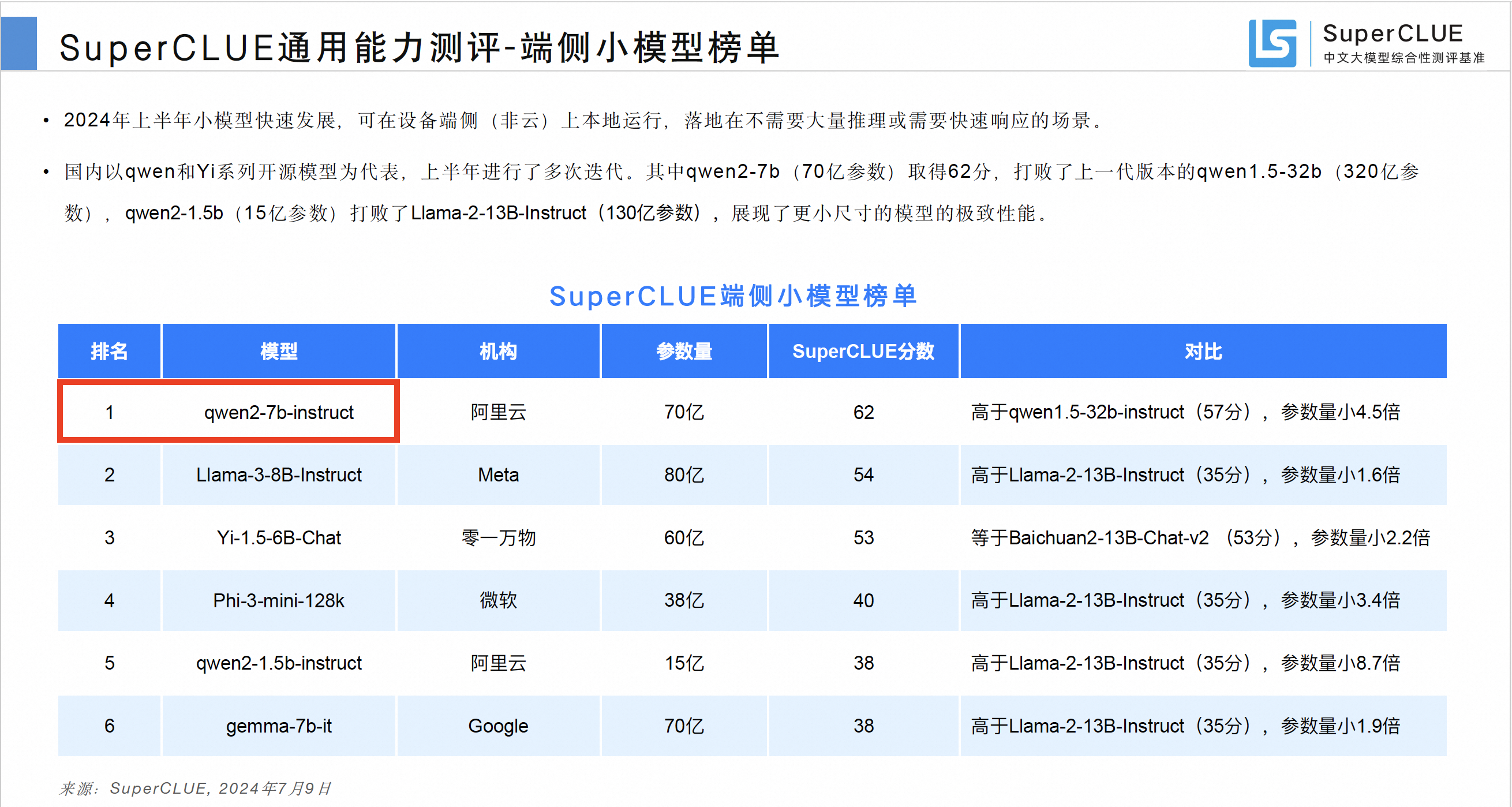
报告同时公布了端侧小模型测评榜单,通义千问 70 亿参数开源模型 Qwen2-7B 排名第一,打败了上一代版本的 Qwen1.5-32B(320 亿参数)和 Llama-3-8B-Instruct(130 亿参数),展现了更小尺寸的模型的极致性能。报告认为,2024 年上半年端侧小模型进展迅速、表现惊艳,极大提升了落地的可行性。
据悉,Qwen2 是阿里在今年 6 月推出的通义千问第二代开源模型,已先后登顶国内外多个权威榜单,引领中国开源模型强势崛起。Qwen 系列开源模型下载量已经突破 2000 万次。SuperCLUE 报告点评:「综合来看,Qwen2-72B 整体能力不俗,引领全球的开源生态,是一个非常有竞争力的通用开源大模型,可应用于推理、数理分析、信息处理或相对专业复杂场景,重点推荐应用于工业、金融、医疗、汽车等垂直专业场景。」
附:
· SuperCLUE 官方推文链接:
https://mp.weixin.qq.com/s/Ke18lStd_hkdM8gXOc6dag
·《中文大模型基准评测 2024 上半年报告》原文链接:
www.cluebenchmarks.com/superclue_24h1


