

上周,OpenAI 在春季新品发布会上公布了最新的 GPT-4o,并展示了一系列令人瞩目的新功能。作为一款全能模型(Omnimodel),GPT-4o 融合了文本、语音和图像三种模态的理解能力。
上周,OpenAI 在春季新品发布会上公布了最新的 GPT-4o,并展示了一系列令人瞩目的新功能。作为一款全能模型(Omnimodel),GPT-4o 融合了文本、语音和图像三种模态的理解能力。可以接受任何文本、音频和图像的组合作为输入,并直接生成上述这几种媒介输出。这意味着人机交互迈入一个全新的发展阶段。

GPT-4o:多模态实时语音助手,更快更有情感
与现有模型相比,GPT-4o 的核心亮点,当属具备了实时语音交互能力。在语音模式下,GPT-4o 能够实现高质量的语音合成和语音识别。人机对话中,GPT-4o 可以在 232 毫秒内对音频输入做出反应,甚至你还能随时打断,GPT-4o 根据情境生成不同风格的声音和情感给出无缝回复,保证前后自然融洽的连续对话。
OpenAI 的开发负责人 Mark Chen 现场演示了 GPT-4o 的语音交互能力。当 Mark 说要再次尝试深呼吸时,ChatGPT 也恰好接上话题说:「慢慢呼气。」整个过程几乎没有延迟,响应迅速且富有共情,如真人般对话。

相比之下,当前市场上的语音助手大多反应迟缓、不能被打断且缺乏情商。GPT-4o 俨然是一款进阶人工智能语音助手。
AI 大模型 打造人机语音交互范式
从最初不会说话的 AlphaGo,到之后「能说会道」的苹果 Siri 与 ChatGPT 语音版,再到如今的 GPT-4o。通过实时语音、视频输入信息的理解和高度拟人化的语音输出,呈现更具真实感与沉浸感的交互体验。GPT-4o 在人机交互的表现,特别是语音交互中的突破,开启了全新的 AI 超拟人化交互方式。
事实上,紧跟大模型发展,超拟人语音合成作为人机交互的重要表达方式,近来已经成为国内外 AI 巨头争相布局的重点。
相较于传统语音合成中「板正」、「一丝不苟」的「播音腔」问题,超拟人语音合成能够模拟人类的副语言,如呼吸、叹气、语速变化等习惯,使合成效果更接近人在日常生活中的口语表达。无论是轻松的日常聊天,还是复杂的专业问答,机器都能根据对话的场景变化调整语调和情感,让交流变得更加自然真实。
多维度 TTS 音色定制 助推 AI 语音交互商业化应用
标贝科技专注智能语音交互领域多年,在多风格、多情感语音合成上持续深耕。依托核心的语音大模型迁移学习和深度神经网络技术,标贝科技通过分析大量真实语音数据,提取真人说话时的音色、语调、情感等特征,提高对副语言现象的建模能力。最终输出的合成声音在韵律表现、音色层次感、情感拟人化方面均有了大幅提升,MOS 评分达到 4.5 以上,无限接近真人表达。
与传统语音合成技术相比,标贝科技语音合成系统基于 GAN 和 Transformer 机制的高音质语音合成,对不同角色和情感表达的判断更加准确,高效且真实的还原波形。进一步增强了喜怒哀乐等各种类型的情感反馈能力。使得合成的声音能够自然、真实地表达说话者的意图和情感。合成过程中用户还可以随心调节停顿、语速、音量等参数,使用更灵活。
此外,结合当前智能语音产业需求现状,标贝科技不断对产品进行打磨升级,推出包括普通复刻、精品复刻、标准化音色定制的多维度 TTS 音色定制方案。方案支持特定口音、方言、语种等一站式集成定制,可以快速针对特定语言环境和使用场景优化语言模型,提供更自然、更准确的语音输出。
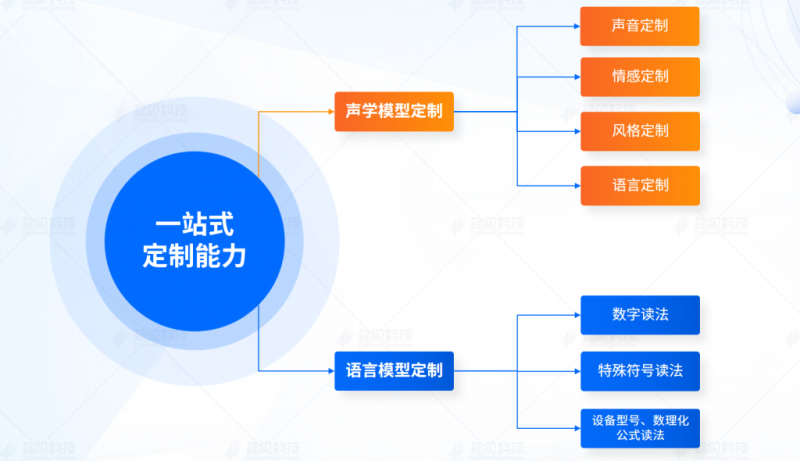
目前,标贝科技多维度 TTS 音色定制方案已经在智能客服、社交娱乐、新闻媒体、数字人、iOT 设备等领域得到应用,助力中国银行、人民日报、湖南电信、恒生电子等多家行业头部企业实现 AI 语音能力的应用与拓展。
GPT-4o 的问世,无疑带来了更智能、更便捷的交流方式,推动人机交互模式的革新,更带动了新一波的个性化语音交互热潮。未来,标贝科技将持续深耕智能语音交互领域,重点发力拟人化语音合成技术创新研发,解锁更丰富的应用场景,为用户打造更加全面和智能的语音交互体验。
来源:互联网


