

能够根据图片识人、答题、创作、写代码
1 月 26 日,阿里云公布多模态大模型研究进展。通义千问视觉理解模型 Qwen-VL 再次升级,继 Plus 版本之后,再次推出 Max 版本,升级版模型拥有更强的视觉推理能力和中文理解能力,能够根据图片识人、答题、创作、写代码,并在多个权威测评中获得佳绩,比肩 OpenAI 的 GPT-4V 和谷歌的 Gemini Ultra。
LLM(大语言模型)之后,大模型领域的下一个爆点是什么?多模态是当前最具共识的方向。过去半年来,OpenAI、谷歌等争相推出多模态模型,阿里云也在 2023 年 8 月发布并开源具备图文理解能力的 Qwen-VL 模型,Qwen-VL 取得了同期远超同等规模通用模型的表现。
视觉是多模态能力中最重要的模态,作为人类感知世界、认知世界的第一感官,视觉传递的信息占据了「五感」信息的 80%。通义千问视觉语言模型基于通义千问 LLM 开发,通过将视觉表示学习模型与 LLM 对齐,赋予 AI 理解视觉信息的能力,在大语言模型的「心灵」上开了一扇视觉的「窗」。
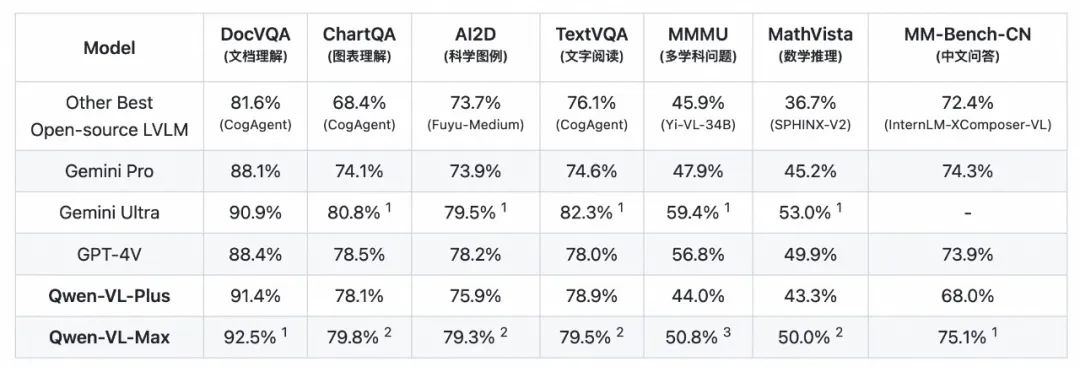
相比 Qwen-VL,Qwen-VL-Plus 和 Qwen-VL-Max 拥有更强的视觉推理和中文理解能力,整体性能堪比 GPT-4V 和 Gemini Ultra。在 MMMU、MathVista 等测评中远超业界所有开源模型,在文档分析(DocVQA)、中文图像相关(MM-Bench-CN)等任务上超越 GPT-4V, 达到世界最佳水平。
基础能力方面,升级版模型能够准确描述和识别图片信息,并且根据图片进行信息推理、扩展创作;具备视觉定位能力,还可针对画面指定区域进行问答。
视觉推理方面,Qwen-VL-Plus 和 Qwen-VL-Max 可以理解流程图等复杂形式图片,可以分析复杂图标,看图做题、看图作文、看图写代码也不在话下。![]()
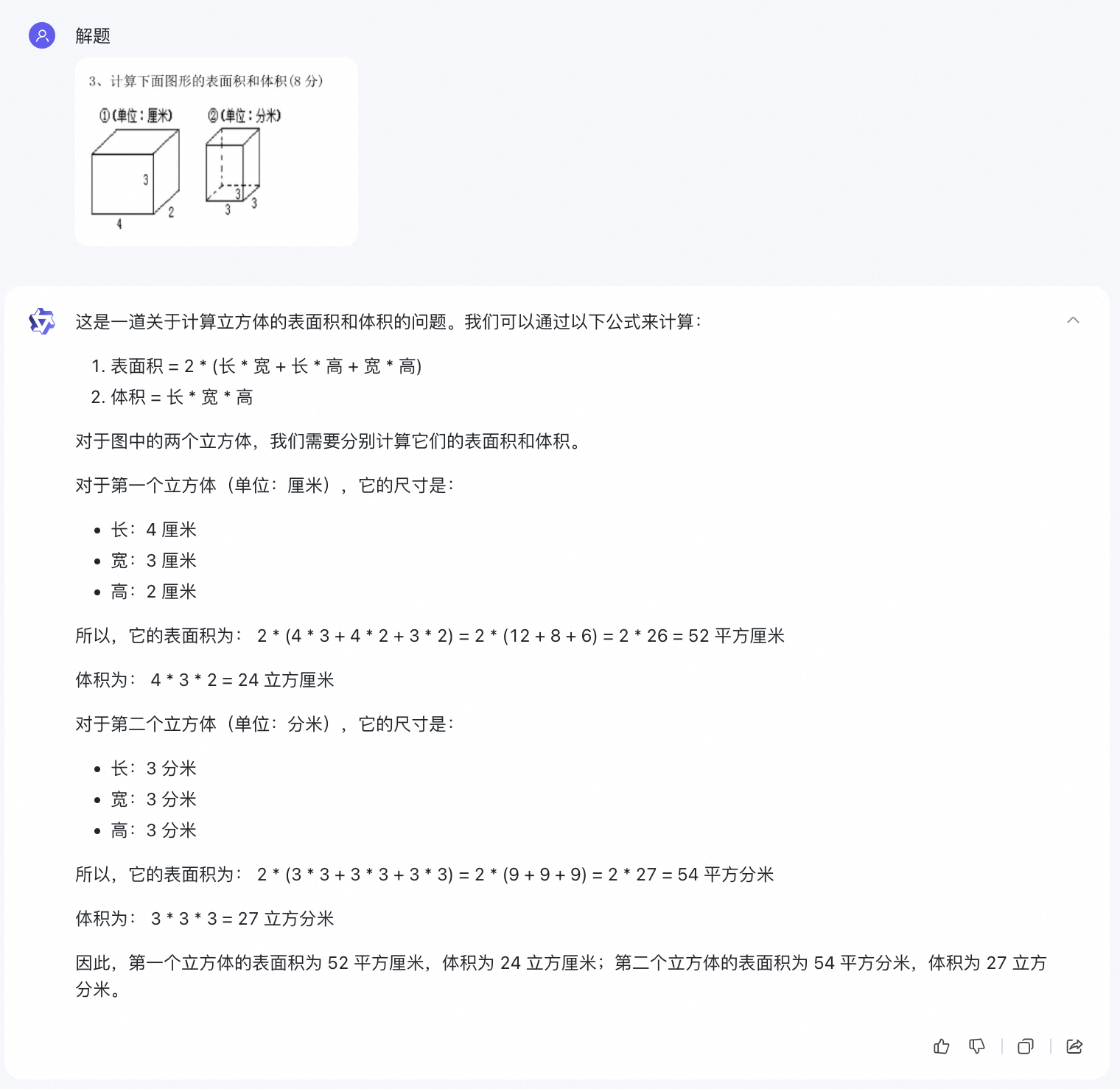
Qwen-VL-Max 看图做题
图像文本处理方面,升级版 Qwen-VL 的中英文文本识别能力显著提高,支持百万像素以上的高清分辨率图和极端宽高比的图像,既能完整复现密集文本,也能从表格和文档中提取信息。

Qwen-VL-Max 复现密集文本
相比 LLM,多模态大模型拥有更大的应用想象力。比如,有研究者在探索将多模态大模型与自动驾驶场景结合,为「完全自动驾驶」找到新的技术路径;将多模态模型部署到手机、机器人、智能音箱等端侧设备,让智能设备自动理解物理世界的信息;或者基于多模态模型开发应用,辅助视力障碍群体的日常生活,等等。
目前,Qwen-VL-Plus 和 Qwen-VL-Max 限时免费,用户可以在通义千问官网、通义千问 APP 直接体验 Max 版本模型的能力,也可以通过阿里云灵积平台(DashScope)调用模型 API。


