

几番「交手」,全球大模型玩家迎来了令人兴奋的「实力值」排行榜更新!
几番「交手」,全球大模型玩家迎来了令人兴奋的「实力值」排行榜更新!
继 11 月初零一万物发布性能优异的 Yi-34B 基座模型后,Yi-34B-Chat 微调模型在 11 月 24 日开源上线,再度获得全球开发者广泛关注,短时间在全球多个英文、中文大模型权威榜单名列前茅。
其中,斯坦福大学研发的大语言模型评测 AlpacaEval Leaderboard 备受瞩目。在实打实的「秀肌肉」比拼中,Yi-34B-Chat 以 94.08% 的胜率,超越 LLaMA2 Chat 70B、Claude 2、ChatGPT,在 Alpaca 经认证的模型类别中,成为世界范围内仅次于 GPT-4 英语能力的大语言模型,并且是经由 Alpaca 官方认证为数不多的开源模型。
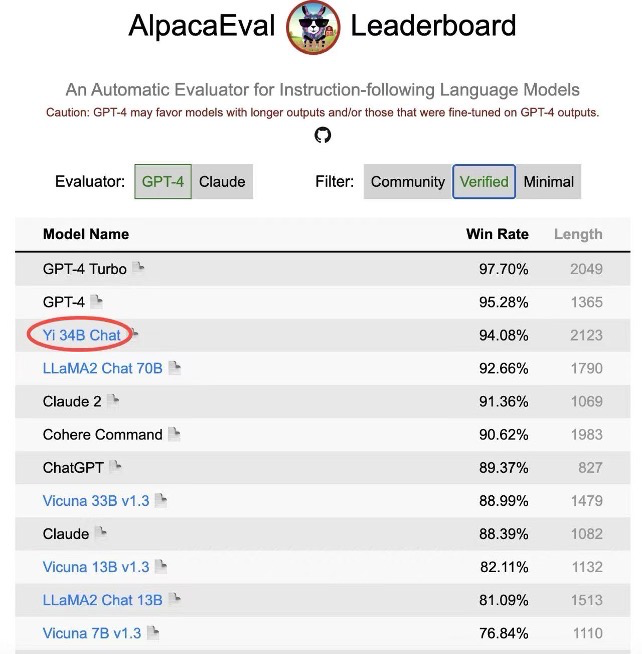 AlpacaEval Leaderboard 排行榜(发布于 2023 年 12 月 7 日)
AlpacaEval Leaderboard 排行榜(发布于 2023 年 12 月 7 日)同一周,在加州大学伯克利分校主导的 LMSYS ORG 排行榜中,Yi-34B-Chat 也以 1102 的 Elo 评分,晋升最新开源 SOTA 开源模型之列,性能表现追平 GPT-3.5。
在五花八门的大模型评测中,伯克利 LMSYS ORG 排行榜采用了一个最为接近用户体感的「聊天机器人竞技场」特殊测评模式,让众多大语言模型在评测平台随机进行一对一 battle,通过众筹真实用户来进行线上实时盲测和匿名投票,11 月份经 25000 的真实用户投票总数计算了 20 个大模型的总得分。Elo 评分越高,说明模型在真实用户体验上的表现越出色,可说是众多大模型评测集中最能展现「Moment of Truth 真实关键一刻」的用户导向体验对决。在开源模型中,Yi-34B-Chat 成为当之无愧的「最强王者」之一(英语能力),LMSYS ORG 在 12 月 8 日官宣 11 月份总排行时评价:「Yi-34B-Chat 和 Tulu-2-DPO-70B 在开源界的进击表现已经追平 GPT-3.5」。
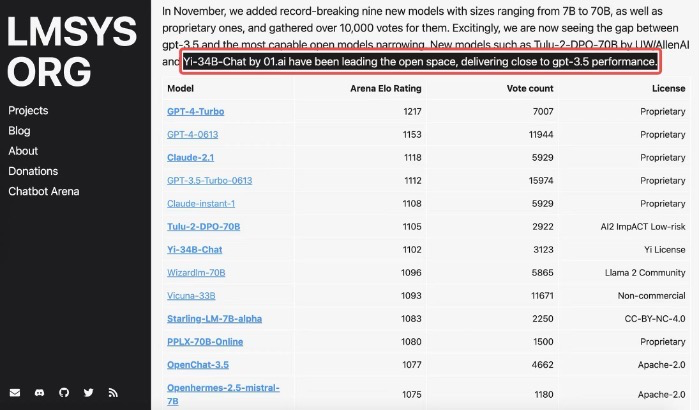 LMSYS ORG 榜单(发布于 2023 年 12 月 8 日)
LMSYS ORG 榜单(发布于 2023 年 12 月 8 日)中文能力方面,Yi-34B-Chat 微调模型同样不遑多让。SuperCLUE 是一项针对中文能力的排行榜,从基础能力、专业能力和中文特性能力三个不同的维度,评估模型的能力。根据 11 月底发布的《SuperCLUE 中文大模型基准评测报告 2023》,11 月下旬首度发布的 Yi-34B Chat,迅速晋升到和诸多国产优秀大模型齐平的「卓越领导者」象限,在多项基准评测中的「SuperCLUE 大模型对战胜率」这项关键指标上,Yi-34B-Chat 取得 31.82% 的胜率,仅次于 GPT4-Turbo。
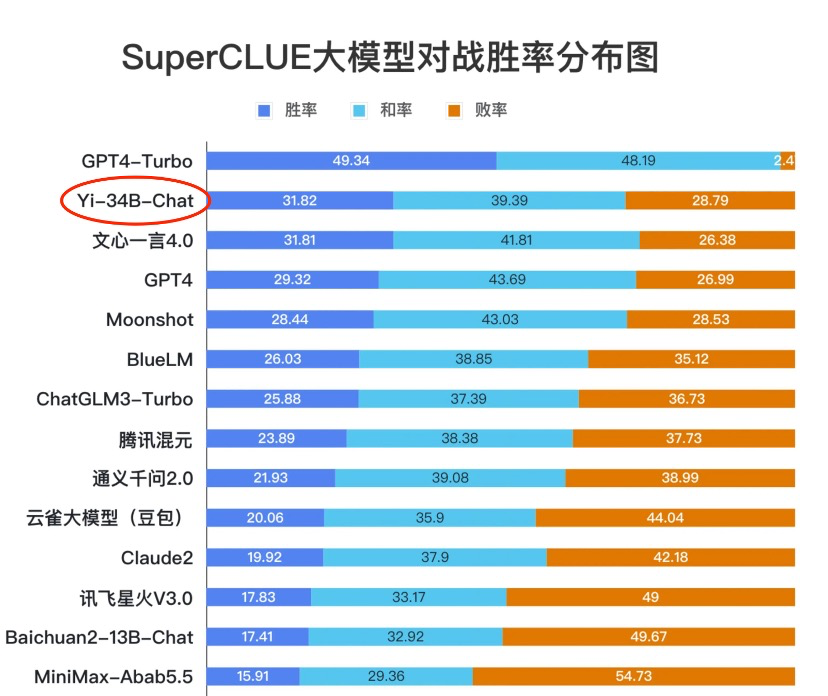 中文 SuperCLUE 排行榜(发布于 2023 年 11 月 28 日)
中文 SuperCLUE 排行榜(发布于 2023 年 11 月 28 日)对广大开发社区来说特别值得一提的是,Yi-34B-Chat 微调模型还为开发者提供了 4bit/8bit 量化版模型。Yi-34B-Chat 4bit 量化版模型可以直接在消费级显卡(如 RTX3090)上使用,训练成本友好。
Yi-34B-Chat 模型实力在不同的对话场景中实力如何?来看几个更直观的问题演示:
【知识与生成】:Transformer 模型结构能不能走向 AGI ?

【创意文案】:给我生成一个小红书文案,给大家安利一只豆沙色的口红。

【中文理解】:小王给领导送了一份礼物后。领导说:「小王,你这是什么意思?」小王:「一点心意,意思意思。」领导:「你这就不够意思了。」小王:「小意思,小意思。」领导:「小王,你这人真有意思。」小王:「也没什么别的意思。」领导:「那我多不好意思。」小王:「是我不好意思。」这个意思到底是什么意思?

据零一万物介绍,除了 Yi 系列强基座的贡献以外,Yi-34B-Chat 模型的效果还得益于其人工智能对齐(AI Alignment)团队采用了一系列创新对齐策略。通过精心设计的指令微调流程,不仅强化了模型在理解和适应人类需求方面的能力,还使得模型与人类价值观对齐,包括帮助性(Helpful),可靠性(Honest),无害性(Harmless)等。
在强基座设定下,该团队采用了一种轻量化指令微调方案,该方案涵盖了单项能力提升和多项能力融合两个阶段。
其中,单项能力包括通用指令跟随、创意内容生成、数学、推理、编程、泛 COT、对话交互等。通过大量的消融实验,针对模型单能力构建和多能力融合总结了独家认知经验。
在数据的量和质方面,一方面,团队在强基座模型上,实现仅需要少量数据(几条到几百条),就能激发模型特定单项能力;另一方面,数据质量比数量重要,少量高质量数据比大量低质量数据更好。通过关注超出模型能力的「低质量」数据,减少了模型「幻觉」。
在指令多样性与难度方面,团队通过在各能力项下构建任务体系,实现了训练数据中的指令均衡分布,大幅提升了模型泛化性。通过复合指令构造和指令难度进化,不仅提升了模型效果,也显著降低了对数据量的需求。
在风格一致性方面,团队发现训练数据的风格会影响模型收敛速度和能力上限的逼近程度,因此统一了回复风格,比如重点设计了 CoT 的回复风格,实现在轻量 SFT 情况下,避免了风格不一致加剧模型的「记忆」现象。
在多能力融合阶段,团队采用网格搜索的方法来决定数据配比和超参数的设置,通过基准测试和自建评测集的结果来指导搜索过程,成功实现模型的多能力融合。
生态与开发者始终是大语言模型的核心。零一万物宣布,邀请全球开发者共同测试使用 Yi-34B-Chat 模型能力,一起搭建 Yi 开源模型的应用生态系!
模型地址
https://huggingface.co/01-ai/
https://www.modelscope.cn/organization/01ai


