

Yi-34B 将支持 200K 上下文,李开复称其多指标击败全球玩家。
作者 | 宛辰、连冉、幸芙
编辑 | 郑玄
11 月 6 日,创新工场董事长兼 CEO 李开复亲自带队的大模型创业公司零一万物,正式开源发布首款预训练大模型 Yi-34B。

李开复将公司的首次公开亮相称为「Yi」鸣惊人,表示 Yi-34B 是「全球最强开源模型」,通用能力、知识推理、阅读理解等多指标击败全球玩家。并称零一万物在数据采集、算法研究、团队配置等环节均为「世界第一梯队」,对标 OpenAI、谷歌等一线大厂。
这次亮相,零一万物也揭开了其团队构成这个神秘面纱的一角。会上,零一万物两位技术副总裁,Pretrain 负责人黄文灏和 AI Infra 负责人戴宗宏,也一同出席。零一万物方面称,团队核心成员拥有 Google、微软、阿里巴巴、百度、字节跳动、腾讯等国内外顶级企业背景,并持续延揽全球范围内最优秀的华人 AI 精英。
而李开复本人,也为零一万物的团队构成做出了最好的背书。作为第一代留学 CMU 的华裔 AI 科学家,经历过微软的 PC 时代,谷歌的移动互联网时代,李开复对 AI Native 应用有异于常人的敏感。不久前,在极客公园组织的西溪论道上,李开复对「什么是 AI Native 的应用」的定义,在产业圈快速蔓延,得到了一致认可。
他提出,AI native(AI 原生)的应用可能有这样的特征:如果大模型拿掉了,应用就崩溃了,它是一个完全依靠大模型能力的应用。在这个视角下,微软 Copilot 可能不算是 all in 大模型的产品,因为拿掉 Copilot,Office 软件还是 Office,AI 只是锦上添花。
对于接下来的计划,李开复剧透,在模型上,未来会陆续宣布更多团队成果,包括:更大尺寸、对话模型、加强的数学和代码模型、多模态模型。除了模型之外,一个 Super APP 的雏形也会在不久的将来跟大家分享。
01 Yi-34B:200K 上下文窗口、登顶 Hugging Face
「Yi」系列大模型的命名来自「一」的拼音「Yi」中的「Y」上下颠倒,形同汉字的「人结合 AI 里的 i,代表 Human + AI 强调以人为本的精神,为人类创造价值。
Yi-34B 拥有全球最长 200K 上下文窗口,可处理 40 万汉字超长文本输入,相比之下,OpenAI 的 GPT-4 上下文窗口为 32 K,文字处理量约 2.5 万字,Anthropic 的 Claude2-100K 上下文窗口也只有 100K 规模。
在语言模型中,上下文窗口是大模型综合运算能力的金指标之一,对于理解和生成与特定上下文相关的文本至关重要。在文档摘要、基于文档的问答等下游任务中,长上下文的能力也发挥着关键作用,应用场景广阔,比如在法律、财务、传媒、档案整理等诸多垂直场景里,如果使用更准确、更连贯、速度更快的长文本窗口功能,就能更高效地提高生产力。
然而,受限于计算复杂度、数据完备度等问题,上下文窗口规模扩充从计算、内存和通信的角度存在各种挑战,因此大多数发布的大语言模型仅支持几千 tokens 的上下文长度。为了解决这个限制,零一万物技术团队实施了一系列优化,包括:计算通信重叠、序列并行、通信压缩等。通过这些能力增强,实现了在大规模模型训练中近 100 倍 的能力提升。
此次零一万物发布的 Yi-34B 的 200K 上下文窗口直接开源,不仅能提供更丰富的语义信息,理解超过 1000 页的 PDF 文档,让很多依赖于向量数据库构建外部知识库的场景,都可以用上下文窗口来进行替代;Yi-34B 的开源属性,也给想要在更长上下文窗口进行微调的开发者提供了更多的可能性。
根据 Hugging Face 英文开源社区平台和 C-Eval 中文评测的最新榜单,Yi-34B 预训练模型取得了多项 SOTA 国际最佳性能指标认可,在一些关键指标上优于包括 Meta 的 Llama 2 在内的领先开源模型,是目前唯一成功登顶 Hugging Face 全球开源模型排行榜的国产模型。
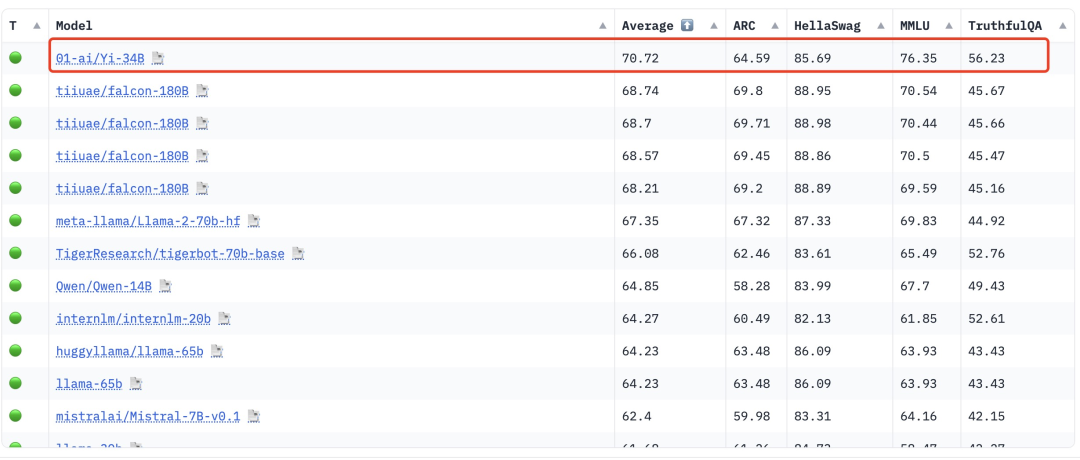
Hugging Face Open LLM Leaderboard (pretrained) 大模型排行榜,Yi-34B 位居榜首(2023 年 11 月 5 日)/图片来源:零一万物
目前,「Yi」有 Yi-34B、Yi-6B 两尺寸可选,均为双语(英文/中文),适合多元场景,对学术研究完全开放、同步开放,商用申请免费。
其中,34B 为性能成本「黄金比例」尺寸,对开发者友好,原因在于其相比目前开源社区主流的 7B、13B 等尺寸,34B 具备更多知识容量+多模态能力;达到了「涌现」门槛;可实现高效率单卡推理;满足了精度要求以及训练成本友好。
同时,李开复宣布零一万物已启动下一个千亿参数模型的训练,接下来也将快节奏推出 Yi 系列量化版本、对话模型、数学模型、代码模型、多模态模型等。
在李开复看来,就大模型而言,模型的参数规模仍然是最重要的,需要继续扩大模型大小,同时要注意数据质量、训练稳定性等问题;同时,Infra 结构也非常重要,要确保可扩展到更大规模,解决大批量并行训练时的系统瓶颈;另外,多模态也是发展的重点方向,要处理好不同模态之间的融合以及编码含义等问题。
零一万物 AI Infra 负责人戴宗宏透露:两千亿模型的前置实验已经做完,在按部就班训练中;针对万亿模型的相关研究工作已经同步开展,希望整个训练过程一棒接一棒地持续滚动下去。
02 AI Infra 是护城河
训练一个出色的大模型,最重要的是拥有高质量的数据。
零一万物强调其对大模型的数据筛选能力,让它获得了更多高质量的数据。首先,它先用 AI 做筛选,再进行人工评估、不断迭代,其数据滤除率约为同行的十分之一。其次,它的英文语料要高于中文语料,因为英文语料的质量更高。
此外,团队花了很多时间研究 Scaling Law(规模定律,指在某些系统中,随着系统规模的增加,某些性能指标呈现出特定的变化趋势)。也就是说,团队先在小模型上做好了数据配比和评估,并将其推演到百亿、千亿、甚至万亿规模的模型上。
零一万物自研出一套「规模化训练实验平台」,数据配比、超参搜索、模型结构实验都可以在小规模实验平台上进行,对 34B 模型每个节点的预测误差都可以控制在 0.5% 以内。
这可以提高训练的效率、降低训练的成本,「整个训练是一个动力学过程,中间每一步都可以通过数学方式预测出来,而不需要做大量的实验。」零一万物技术副总裁及 Pretrain(预训练)负责人黄文灏说。
如果说训练大模型是登山,那么 AI Infra(AI Infrastructure 人工智能基础架构技术)则定义了大模型训练算法和模型的能力边界——用登山做比喻,如果说训练大模型是攀登山峰,那么 Infra 就是提供后援的基地。
具体来说,AI Infra 主要为大模型训练和部署提供各种底层技术设施,包括处理器、操作系统、存储系统、网络基础设施、云计算平台等等。
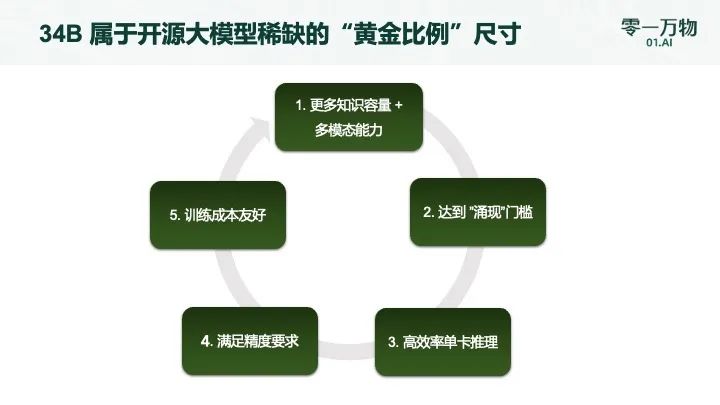
零一万物解释为什么选择 34B 的规模,图源 | 零一万物
零一万物团队表示,AI Infra 支撑了其超行业水平的训练效果。通过 AI Infra,Yi-34B 模型的训练成本实测下降了 40%——如果说别的公司需要 2000 台 GPU 训练一个模型,那么零一万物可能只要 1200 台——进一步模拟上到千亿规模训练成本可下降多达 50%。
截至目前,其 AI Infra 能力能实现故障预测准确率超过 90%、故障提前发现率达到 99.9%、不需要人工参与的故障自愈率超过 95%。这很好地保障了模型的训练过程。
AI Infra 能力的背后是人才。李开复曾表示,做过大模型 Infra 的人比做算法的人才更稀缺。零一万物称,其拥有一支行业稀有的 AI Infra 技术团队。
零一万物 AI Infra 的负责人戴宗宏,是前华为云 AI CTO 及技术创新部长、前阿里达摩院 AI Infra 总监。他带领的这支 Infra 团队,核心成员是来自阿里、华为、微软、商汤等公司的技术专家,曾参与支持过 4 个千亿参数大模型规模化训练,管理过数万张 GPU 卡,有很强的端到端全栈 AI 技术能力。
在完成 Yi-34B 预训练的同时,李开复也宣布即将启动下一个千亿参数模型的训练。「零一万物的数据处理管线、算法研究、实验平台、GPU 资源和 AI Infra 都已经准备好,我们的动作会越来越快。」他说。
03 下一站,打造 Super App(超级应用)
几个月来,零一万物的进展不可谓不顺利:
-
3 月 19 日,李开复在朋友圈发英雄帖,官宣组建零一万物团队,定位是 AI 2.0 全新平台和 AI-first 生产力应用的世界级公司;
-
3 个月后,团队写出第一行代码;
-
7 个月后,零一万物携最新开源产品亮相——Yi-34B 和 Yi-6B;
据悉,零一万物已完成新一轮融资,由阿里云领投。当前,零一万物估值已超 10 亿美元。
接下来,零一万物将基于 Yi 系列大模型打造 To C 的 super APP(超级应用)。「除了模型之外,我们还在做什么样的工作?一个 Super APP 的雏形也会在不久的将来跟大家分享。AI 2.0 时代,最大的商机一定是超级应用,而这超级应用一定很可能是在一个消费者级别的超级应用,面向海内外的 ToC 超级应用。」李开复在会上说道。
李开复认为,super APP 会是新时代下最大的商机,大模型的存在会是当中的「must have」,甚至未来的内容应该主要是由 AI 来创造,人来帮忙,也就是「AI First」。
考虑到 AI 1.0 时代有些做不出收入的公司被淘汰的前车之鉴,李开复谈到,在 AI 2.0 时代,做出收入,并且是「持续做出高质量收入」就非常重要,零一万物接下来的 APP 以及未来的 Super APP 都应该基于上述原则去推动与发展。
他强调,「AI 2.0 是有史以来最大的科技革命,它带来的改变世界的最大机会一定是平台和技术,正如 PC 时代的微软 Office,移动互联网时代的微信、抖音、美团一样,商业化爆发式增长概率最高的一定是 ToC 应用。」

11 月 6 日,李开复在零一万物线上发布会中答记者问|截图来源:极客公园
他认为,如果 PC 时代赋予给开发者用户的机会,是 computer on every Desktop;移动互联网带来的可能是基于位置的、个性化的、随时随地的计算;AI 2.0 时代带来的巨大机会,就是把一个超级大脑对接、赋能给每一个应用。
基于上述判断,零一万物选择在 AI 2.0 时代,开发最好的大模型底座、行业模型,一边寻找最大的商机——一个消费者级别的超级应用。
对于做 Super APP 的方法论,李开复认为一定是一个很简单的开始,用精益创业的方法不断地迭代。就像抖音和微信的第一个版本,并不是超级应用,而是捕捉到了用户需求,并用新平台的技术精髓,做一个大家喜欢的简单应用,然后根据用户反馈不断调整,最终迭代成为超级应用。
零一万物的路径选择,也是 AI 2.0 创业潮的产业缩影。开源、闭源并线进行,基础模型和超级应用都做,甚至 ToB、ToC 的商业化同时探索。
这在过去是罕见的,因为 ToB 和 ToC,意味着公司组织、DNA、团队的技术构建方式不一样,原来做用户产品的,很难想象一夜之间能服务 B 端客户。但在大模型这个高门槛、高不确定性的创业赛道上,同时兼顾,已经成为大家共同的选择。


