

「日日新」大模型体系,全面开放 API。
当人们纷纷猜测,GPT-4 的参数量,将会在 GPT-3 的 1750 亿参数的基础上如何再增加时,OpenAI 选择了不公布。这种期待也反应出了一种普遍认知:随着参数量级的增加,模型的能力会再次跃升。
「今天我们衡量一个模型能力的时候,不能够简单来看模型的参数量,而是在以有限的计算量的前提下,来分配资源给参数或者是训练的数据。」4 月 10 日商汤的科技交流会上,CEO 徐立在开场给出了自己的观点。
这场为时长一个半小时的发布会上,大部分的时间用于实时演示。跟随着在舞台一侧、连接大屏幕的电脑,观众看到了商汤大模型,用于多轮对话、文本和图像生成、3D 视觉生成、以及实时互动的各项能力。
大模型是计算「暴力美学」的胜利,描述模型的能力,需要用到参数规模和训练的数据集。商汤认为,大模型的参数量乘以处理的数据量,就能得到模型的计算量。「未来讨论大模型,希望大家讨论的是它的计算量,这才是它的能力。」
扎进人工智能领域 9 年,见证了深度学习到大模型时代更替,商汤也以这场技术交流会,展示了自己将拥抱大模型,并提供全面服务的姿态。
这既包括在通用大模型上的持续推进,也包括结合已有的场景、数据、算力设施优势,推进大模型的行业应用。商汤认为,多模态大模型的下一步,将是通用人工智能,「我们也会将 AGI 作为核心的发展目标,在未来几年持续推动大模型和 AGI 技术的突破。」徐立说。
01 日日新大模型体系
在技术交流会上,商汤科技董事长兼 CEO 徐立发布了「日日新 SenseNova」大模型体系,分别展示了在自然语言生成、图片视频内容生成、3D 建模实时交互上的能力。
之所起名为「日日新」,是寓指大模型通过数据闭环,不断提升能力。「这代表人工智能大模型,在以周为单位的数据输入上,可以日日更新,能力日日增强。」

商汤 CEO 徐立介绍「日日新 sensenova」大模型体系
技术路线图显示,商汤在 2019 年开始探索大模型,训练了 10 亿参数级别的视觉大模型,到了 2022 年,已经训练了 320 亿参数级别的大模型。
前不久的 3 月,商汤开源了有 30 亿参数的书生 2.5 多模态大模型。在架构上,运用兼容解码的 Uni- Perceiver 架构。这是为了将图像、视频、语言不同模态的信息,以同一种方式在一个空间进行编码。这样的设计也体现了商汤对未来模型发展的思考,希望能够以一个更强大的底层模型,兼容不同的下游任务。
此次的「日日新 SenseNova」大模型体系不同场景的演示,也展示了商汤较为全面的技术积累。
自研语言大模型「商量」
作为商汤自研的中文语言大模型应用平台,「商量」具有语言理解、生成能力,现场演示了不同场景、领域的应用。
在文字创作方面,通过多轮对话,「商量」能够按要求生成宣传语,并在此基础上写作新产品邀请函;而通过对话引导,它也能够辅助写作适合儿童阅读的童话故事。此外,「商量」也具有处理长文本的能力,能够阅读 PDF 后,回答用户提出的针对性问题。
除了基本的语言模型,发布会现场还展示了基于语言能力的两个扩展场景:编码能力、以及基于医学专业知识的对话咨询。徐立表示,「商量」接入了自然语言编程的能力后,80% 的代码可以通过提示词生成,人工手写的部分只剩下 20%。此外,使用某个垂直领域的公司代码进行微调后,即能够帮助公司内部的程序员共享编程经验,增加开发能力。商汤内部实测显示,使用了编程工具后,代码的编写效率提升了 62%。

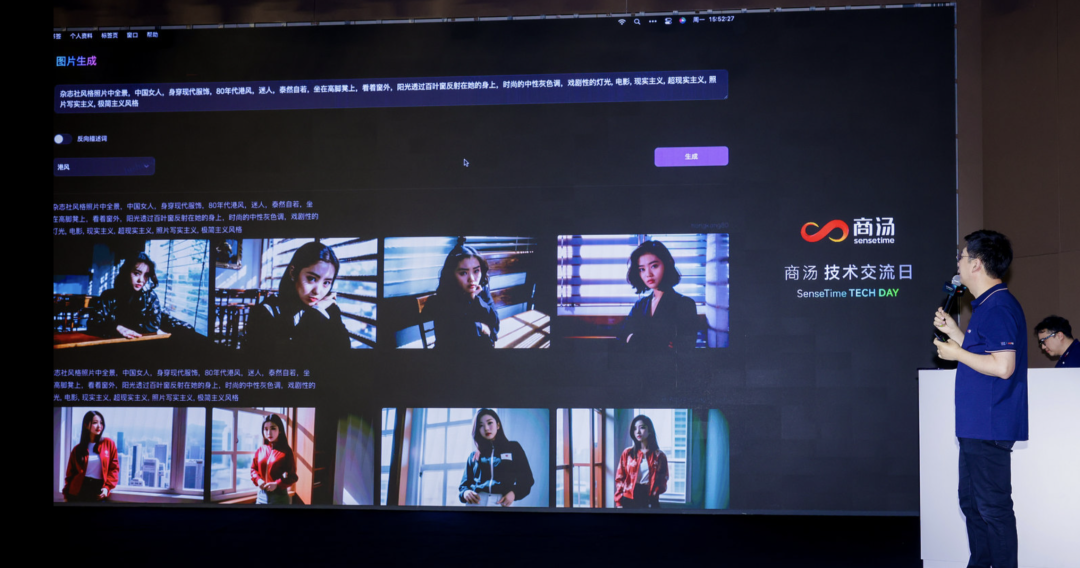
文生图大模型「秒画」
AI 作画的能力已经成为大模型的「标配」,发布会现场展示了基于一长串的修饰词的 Prompt 生成图片的能力。修改 Prompt 里的个别描述短语(比如「穿西装」改为「穿汉服」),模型能够快速生成与之相匹配的图片。
除此之外,「秒画」还支持用户上传 20 张图片,供模型学习风格。在现场的演示中,工作人员上传了 20 张「港风」的明星图片,几分钟后,学习完成,模型就能够学会生成具有「港风」的人像。
数字人生成平台「如影」
基于「如影」平台,用户上传一段符合要求的视频,即可生成自己的孪生数字人,并在此基础上使用平台的工具,生成想要的背景图片、文字段落、以及根据文字生成语音,最终集成为一段数字人做演示的短视频。
在现场展示中,工作人员让 AI 生成一段介绍丝绸之路的文字,再分别翻译为英语、阿拉伯语两种不同的文字,让数字人分别用对应的语言进行介绍。

3D 内容生成平台「琼宇」与「格物」
在 3D 建模的生成领域,商汤分别展示了城市空间、建筑、园区的生成平台「琼宇」,与对普通物品扫描后进行 3D 建模的「格物」。
基于这两个平台,以及「如影」的数字人平台的综合能力,能够实现人、物、场的便捷编辑创作。徐立介绍,要实现便捷的编辑能力,难点在于实现实时的渲染。这一能力能够应用到游戏设计、空间效果的创意设计、虚拟人直播等领域。

02 从「小模型」到「大模型」,带来研发体系变革
从 2018 年谷歌的 Bert、GPT-1 先后诞生,大模型的技术路线便初露雏形。到了 2022 年底,ChatGPT 这样的现象级产品,正式标志了人工智能大模型的产业时代来临。「AI2.0 时代的平台式变革」、「AI 的 IPhone 时刻」、「不亚于 PC 和互联网的诞生」,人们用不同的方式去形容这一时刻。
大模型突破了以往深度神经网络处理个别任务的性能天花板。在到达了百亿参数级别后,模型在处理任务的表现上出现了明显突破;其次,一个底层的通用模型,具备了泛化能力,在不同的任务上都有出色的表现。
通用人工智能大模型带来了人工智能范式的变化,商汤科技联合创始人、首席科学家王晓刚表示,在这个时间点上,「也带来商汤自身研发体系的变革」。
在过去,AI 落地的方式是「小模型+场景」,这种形式下,针对每个不同的场景,都会训练一个专用的模型。这就导致了成千上万个模型散落在不同的长尾场景中,研发成本高,周期长,每解决一个新问题,就需要训练新的模型。

以辅助驾驶系统的为例,在「学校区域」指示牌前需要减速这个指令的执行,每一个环节都是一个针对子任务的专用模型进行执行。首先需要经过「物体检测」识别指示牌;其次需要通过「文字识别」理解指示牌的文字内容;最后通过「决策模型」进行决策,确定减速。
当有了大模型的多模态和思维链能力后,给定图片后,只需要输入「这个图标是什么意思?我们应该做什么?」大模型就能够根据已有的信息进行推理,作出将降低车速的决定。这也是 GPT-4 最新展现出的基于多模态信息的推理能力。
「大模型出现后,可以不断的去解锁这个模型新的功能,以极低的成本,非常高效的方式去不断的去解决各个领域里面新出现的各种开放性的任务。」王晓刚介绍。
除了以更高效的方式解决问题,大模型还能够带来系统能力的提升。商汤科技联合创始人、大装置事业群副总裁陈宇恒介绍,视觉大模型能够解决小模型时代自动驾驶中 Corner Case 的痛点。以往的模型会在吸收新的 Corner Case 的时候遗忘更早期的数据,而大模型的学习能力能够解决数据遗忘的问题。
因此,大模型可以通过数据驱动、参数规模不断突破性能,而在实际应用中,可以通过知识蒸馏等方法,以小模型的方式,将大模型的能力部署到车辆或者其他端侧,实现高性价比的方案。

商汤首席科学家王晓刚介绍数据标注服务
商汤的技术强项是计算机视觉,通过预训练大模型,也能够更有效地做图像数据的预标注和筛选。「可以快速地解决原来海量的数据回流后的数据预筛选和标注的问题。」相关的标注效率能够提升 4 倍以上。
王晓刚称,比此前人工智能产业化面临的问题「周期长、落地成本比较高」,而大模型的出现将为行业带来新的转机,「能够以一个模型去解决各个场景里面的这些问题,会极大的推广各个领域的应用。」
03 大装置+大模型,AI 服务的延伸
大模型需要在多张卡上实现超大规模并行计算,这就涉及到分布式计算的工程实现和算力调配等关键能力。
这次的技术交流日,在上海的临港 AI 大装置进行。这也是 2022 年初正式启动的「商汤人工智能计算中心」。目前是亚洲最大的智算平台之一。这也是商汤大模型体系所展示的多项能力的算力基础。
商汤介绍,目前大装置拥有超过 27000 张 GPU 卡,可以输出 5000PetaFlops 的算力。大模型的基础条件是算力资源,ChatGPT 依托微软的智算集群,才能实现暴力计算后的优异结果。而为了更好地服务大模型的训练,微软也专门为其打造了基础设施。「去造超级 AI 计算机去完成任务,训练人工智能大模型,我认为是工程的奇迹。」陈恒宇表示。

在多卡的并行计算上,商汤很早就开始探索。在 2018 年,商汤就探索了 1000 块 GPU 的并行计算能力。目前,大装置能够最大以 4000 卡的规模集群进行单任务训练,并且可以做到七天以上的不间断稳定训练。陈宇恒介绍,这背后有两个方面的技术难点。
首先,要保证多卡并联的计算效率。这需要「通过一个很好的系统架构和网络架构设计,把这么多 GPU 高效地连接起来去做通讯,使它们可以有非常高的并行效率」。目前,商汤在千卡级也能够达到 90% 以上的线性度。这意味着 GPU 规模增加的情况下,单卡性能依旧发挥出色。
其次,要实现长时间、无故障的运行时间。用 100 张卡去做联合训练的情况下,每天会有 0.1 张卡的故障。随着集群增加,故障的卡数就会随之增长。因此,大规模的 GPU 运算需要解决硬件的可靠性、软件的容错度,这在分布式系统的设计上和软件框架的设计上,提出了很大的挑战。
「商汤得益于过去的经验,在这两方面也有很好的技术积累。」陈宇恒表示。
在 2022 年,大装置除了支持自己的大模型体系训练,商汤已经作为算力服务方,服务了其他 8 家客户的大模型训练。王晓刚表示,商汤的特殊之处在于,这些年一直将自己作为「人工智能的平台型的公司」,投入了很大的资源进行基础设施建设。
大模型能力是在原有算力能力上新的叠加层。「商汤没有云,其实是个误解。」陈恒宇表示,商汤一直对外提供 AI 原生的算力、存储网络、软件等不同的服务。

生成式 AI 大火后,商汤也提供大模型的训练、推理、数据管理,以及基于「日日新」大模型体系的 API 服务,甚至是提升生产效率的整套工具链,让政府和行业客户去高效地开发人工智能大模型。


