

论整活,没有一家自动驾驶企业能比特斯拉更专业。
论整活,没有一家自动驾驶企业能比特斯拉更专业。
早在去年 AI DAY 上,特斯拉就宣布放弃激光雷达,走基于摄像头的纯视觉感知路线;而在今年 AI DAY 上,特斯拉则又表示:因为我们的纯视觉自动驾驶技术方案实在太强了,所以我们决定,把超声波雷达也取消掉。
相比还在内卷传感器硬件的其他自动驾驶企业,这一次的特斯拉显得非常极端,但事实上,FSD 早就尝试去除摄像头外的任何传感器数据了。

这意味着我们不得不面对这样一个现实,纯视觉自动驾驶并非信口开河,而特斯拉也做到了,成为行业内当之无愧的领军者。
但是骡子是马,终究要牵出来遛一遛的。尽管 FSD 在北美一路高歌猛进,但在国内却始终有些水土不服,这给了国内自动驾驶企业追赶的机会。
而在追赶者中,新创自动驾驶独角兽公司毫末智行最值得关注。由于在技术研发与技术理念方面与特斯拉颇为相近,毫末智行曾被不少媒体称之为「中国版特斯拉」。
但不同于追求纯视觉的特斯拉,毫末智行并没有选择无脑追随,而是仍然采用「激光雷达+摄像头」的多模态传感器路线,这使其能够更好地适应国内复杂多变的交通环境,兼顾安全性、舒适性与高效性。

不久前,毫末智行在其 AI DAY 技术日上,分享了毫末得以快速进步的观点,那就是以「数据驱动」逻辑去推动自动驾驶技术更新。此外,毫末智行也在长城汽车规模化量产能力的帮助下,仅用短短两年多时间就发展成为了国内头部自动驾驶选手之一。
只是相较数据闭环已经建成、FSD 规模落地的特斯拉来说,毫末智行才刚刚发布了打通高速域与城市域的 HPilot 3.0,累计行驶里程也刚刚超过 2000 万公里。
这不由得引发了人们的进一步联想,如果忽略特斯拉与毫末智行在迭代进度方面的差距,在二者所选择自动驾驶技术路线中,究竟哪一个更具前景、更能满足人们对自动驾驶技术的期待呢?
强软硬件工程能力,让特斯拉 FSD 飞速进化
「一直被模仿,从未被超越」,尽管很多人不愿意承认,但特斯拉一直扮演着自动驾驶技术风向标的角色,其中所依靠的,便是其能够将脑中所想转化为现实的能力。
众所周知,马斯克是第一性原理的忠实信徒。在第一性原理的指引下,马斯克并不会盲从行业既定标准行事,这使他能够摆脱众多思维桎梏,想别人不敢想,做别人不敢做。
基于纯视觉的自动驾驶技术路线便是由此而来的。马斯克认为,既然人类靠视觉感知万物,自动驾驶也应当如此,所以使用激光雷达等硬件的融合感知方案是没有必要的。
和摄像头不同,激光雷达虽然「看不见」,但能够提供高精度的 3D 数据,这使其能够与摄像头形成互补,帮助自动驾驶建立更真实的感知世界。
基于「数据驱动」逻辑,特斯拉采用大数据与大模型训练视觉感知,其第一步就是引入 Transformer 大模型,让特斯拉有了训练海量数据的能力。
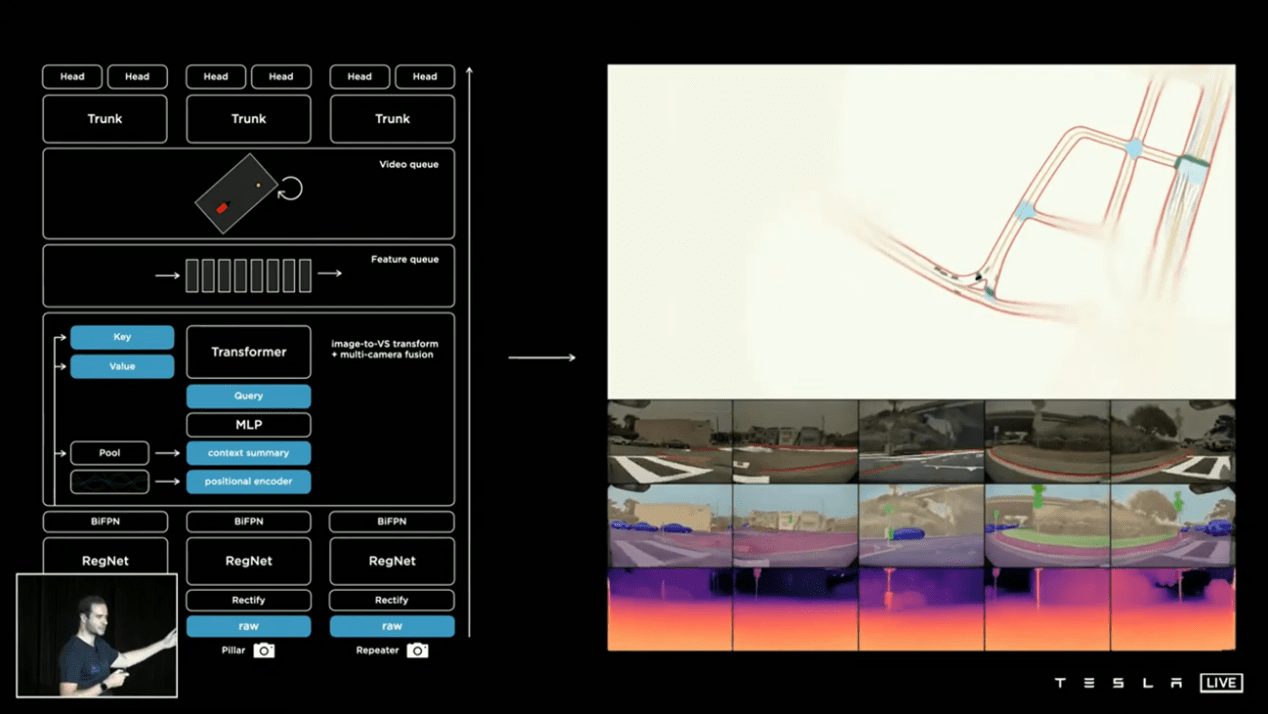
Transformer 对纯视觉感知的作用是非常关键的。因为特斯拉的感知算法思路是,先将多个摄像头获取的 2D 图像数据进行前融合,再使用 Transformer 进行训练,实现特征从 2D 图像空间到 3D 向量空间的变换。
在借助 Transformer 提升感知算法后,不仅激光雷达优势不再,毫米波雷达、超声波雷达也对自动驾驶没有了价值。由此特斯拉才敢于像文章开头那样,对超声波雷达说不。
而在这之后,特斯拉又引入了 Occupancy 网络作为第二步,用于进一步精细视觉感知能力,化解当前以 BEV 网络为代表的视觉感知算法的不足。
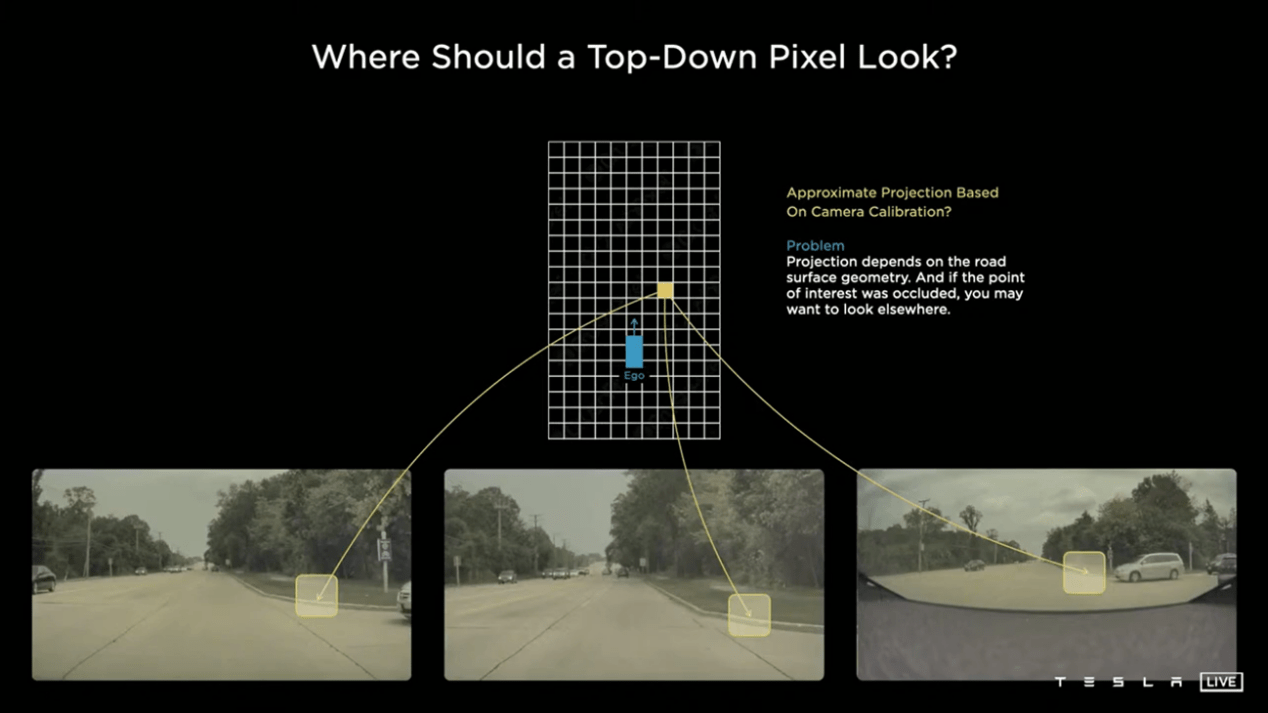
具体来看,此前特斯拉 BEV 网络的思路是,用 2D 网格来表示检测物体,但这种方法显然很难处理诸如侧面延伸出障碍导致超宽的车辆、垂直的路牌等物体。
另外,此前感知系统能够成功检测物体,也非常依赖数据库本身,此前特斯拉追尾一台翻车的白色货车,就是因为后者并不在数据库中,导致感知系统没能成功检测并识别。
对此,Occupancy 网络的解法是,将原本 BEV 的稀疏 2D 网络升级为更加稠密的 3D 网络,并对感知系统检测到的所有物体进行网格内的标注。

这不仅帮助感知系统跳过了「先问是什么,再问怎么做」的规则,更能由此直接建立一个拥有完全计算机语义的世界,将感知能力整体向前推进了一大步。
但在由此提升自动驾驶能力的同时,超高的标注效率又给算力提出了极大的压力,因为供应商提供的通用平台无法满足要求,而如果选择定制,由此带来的成本也将很难平衡。
经过综合考量,特斯拉以自研的 D1 芯片,以及由 D1 芯片组成的 Dojo 超算中心实现了对供应商算力平台的替代。由于 D1 芯片的研发目标之一就是与特斯拉视觉感知算法实现完全拟合,这也使得后者能够完全释放,带来远超所有竞争对手的感知能力。
另一方面,特斯拉还在这一过程快速掌握了算力芯片的研发与生产能力,这对任何一家完全缺乏相关经验的企业来说,都是难以想象的,可见其工程实现能力之强。
最关键的是,软件与硬件同步发展,不仅彼此都做到了高度拟合,还将保证「降本增效」的目的。这让特斯拉有底气将 FSD Bate 版从小范围测试快速推向十几万人,并且在不久的未来,面向所有用户开放。
多模态前融合感知+安全冗余,造就毫末感知智能「双保险」
虽然特斯拉在自动驾驶研发速度上一骑绝尘,但要想征服复杂多变的真实道路场景,实际仍有很多难题需要得到解决。
在毫末智行看来,视觉感知虽然是目前最重要的感知能力,但当下纯视觉感知并不能成为当前实现自动驾驶的最优解。
第一点原因在于,纯视觉技术方案可能在现阶段并不适合国内更加复杂多变的道路交通场景,有太多的变量需要自动驾驶提防,这会给感知系统带来不小的压力。
第二点原因在于,纯视觉技术方案需要自动驾驶企业付出极高的成本实现,特斯拉的强软硬件整合的工程能力,是其他自动驾驶企业很难短时间具备的。
第三点原因在于,激光雷达成本的降低,使得雷达上车不再「压力山大」,而是能够发挥更好的感知冗余的作用。
对此,毫末智行的做法则是,坚持摄像头+激光雷达的多模态传感器路线,即坚持以视觉感知为主、激光雷达提供冗余感知的「重感知」技术方案。

另一方面,借助 Transformer 大模型的优势,毫末智行也能够使用前融合算法,将视觉感知与激光雷达感知数据进行更高效融合。具体来说,前融合感知在单纯依靠视觉感知存在能力短板的情况下,依靠激光雷达、毫米波雷达等多模态感知来弥补视觉缺陷,提升召回率,增强感知效果。
毫末智行也能利用激光雷达建立的点云信息,在进一步提升点云密度的基础上加以标注,使得激光雷达能够轻松为视觉感知进行验证;这不仅也能模拟出类似特斯拉 Occupancy 网络的效果,还有效控制了实现成本。
毫末认为,大规模多模态数据还可以让纯视觉能力提升更快,提升成本更低。通过多模态感知保证冗余感知的同时,毫末通过前感知融合进一步提升感知能力,实现方式则是进一步挖掘现有优势,实现「降本增效」。
从以上可以看出,相较于特斯拉 FSD 的各种「科技与狠活」,毫末智行的多模态融合感知以及安全冗余方案相当于为自动驾驶技术提供了一套「双保险」,成为一种更稳妥的选择。
自动驾驶的「条条大路通向罗马」?
尽管在研发及落地进度上存在一定差距,但特斯拉与毫末智行却都在各自的技术演进中掌握了一套属于自己的核心能力,呈现出各具特色的竞争态势。
特斯拉坚持纯视觉技术路线,并为此修炼出了强大的软硬件工程能力与整合能力,由此实现了 FSD 大跨步进化。特斯拉在纯视觉路线将会「一往无前」。但也存在被「打脸」的风险,比如,会把舍弃的毫米波雷达再亲自装回去,比如,特斯拉无时无刻不在工作的视觉系统会成为侵犯隐私和采集数据的终端。这些是特斯拉在进化中要考虑的问题。
同样掌握「量产」与「数据」能力,毫末智行选择了更为务实、更成熟的多模态融合感知方案,在快速提升城市场景的感知能力的同时,也有了更多安全冗余的保证。
不过,从根本的技术实现逻辑来说,特斯拉与毫末智行都遵循「数据驱动」的发展规律,利用大模型与大数据升级感知算法、并以更高效、低成本实现数据获取和学习训练,可以说是殊途同归。而这一发展路线也逐渐得到了更多行业玩家的认可,成了整个自动驾驶行业的共识。
这不仅使特斯拉与毫末智行分别成为国内外自动驾驶技术研发、落地速度最快的自动驾驶企业,也使得自动驾驶从技术高台在走入大众生活中,有了「条条大路通罗马」的直观案例。
来源:搜狐网


