
了解这些工具的运作方式以及如何使用它们,机器学习将大有作为。
3 月 2 日,谷歌在官方博客中发布了一项有关机器学习新发现。谷歌认为,机器学习可以帮助我们更好了解蛋白质有机体的运作方式以及如何使用他们。
DNA 是生命的语言,是记录人类繁衍生息历史的「活化石」。DNA 告诉我们的身体(和其他有机体)要产生哪些蛋白质;而这些蛋白质则是执行从抵御感染到帮助你在即将到来的考试中取得好成绩等重大任务的微型机器。
但事实上,约 1/3 有机体所产生的蛋白质,科研人员目前仍不知道他们的作用。打个比方,就像我们身处一个嘈杂的工厂,虽然会对环绕四周的工具印象深刻,但对当下正在发生的事情却模糊不清。所以,谷歌认为,对于了解这些工具的运作方式以及如何使用它们,机器学习将大有作为。
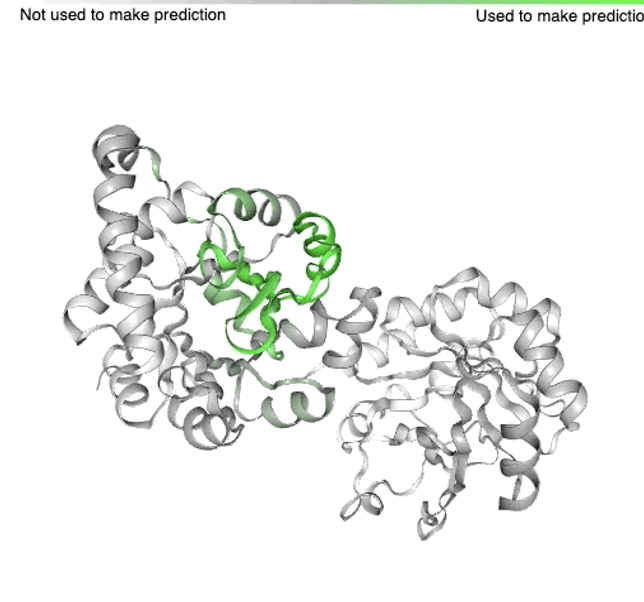
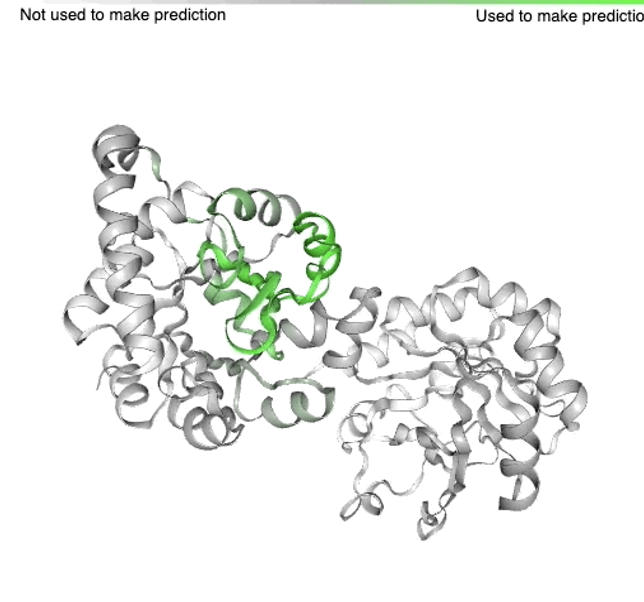
大肠杆菌 TrpCF 蛋白结构示例和 AI 可以预测的功能的区域
这种蛋白质会产生色氨酸—一种我们饮食中所必须摄入的用以保持身体和大脑正常运转的化学物质
最近,DeepMind 展示了 AlphaFold 能够以前所未有的精准度预测蛋白质机制形状。这一预测结果虽然为科研人员研究如何使用蛋白质机制提供非常有力的线索,但它还不能完全解决这一问题。
在发表于 Nature Biotechnology 上的一篇文章中,谷歌描述了神经网络如何能比最先进的技术方法更可靠地揭示蛋白质宇宙中这种「暗物质」的功能。谷歌与 EMBL-EBI 的国际知名专家密切合作,在 Pfam v34.0 数据库版本(一个记录蛋白质家族及其功能的全球资料库)中注释了 680 万个蛋白质区域,超过了数据库过去十年的扩充量,并帮助全球 250 万生命科学研究人员发现新的抗体、酶、食物和治疗方法。
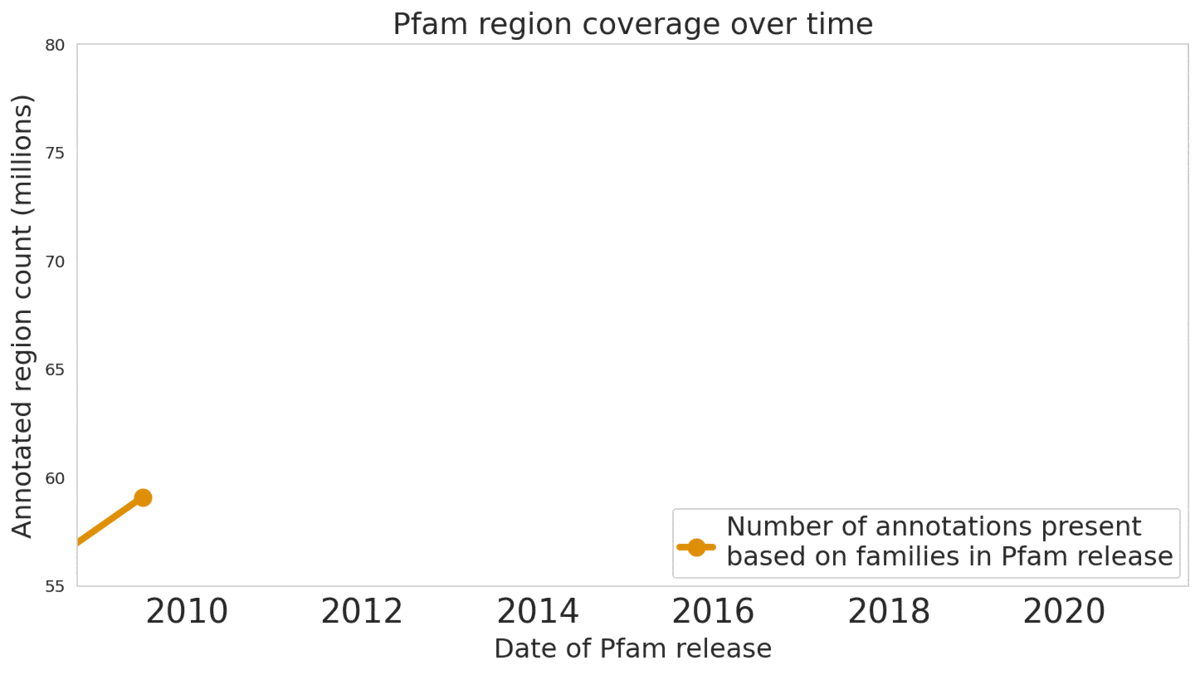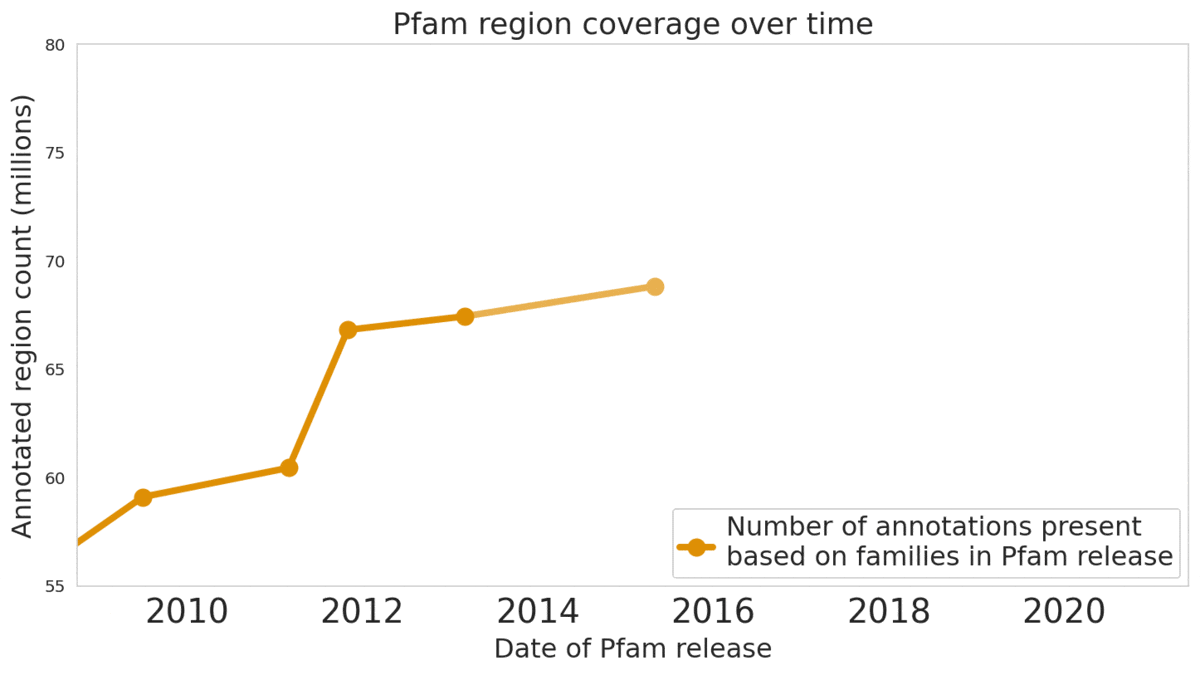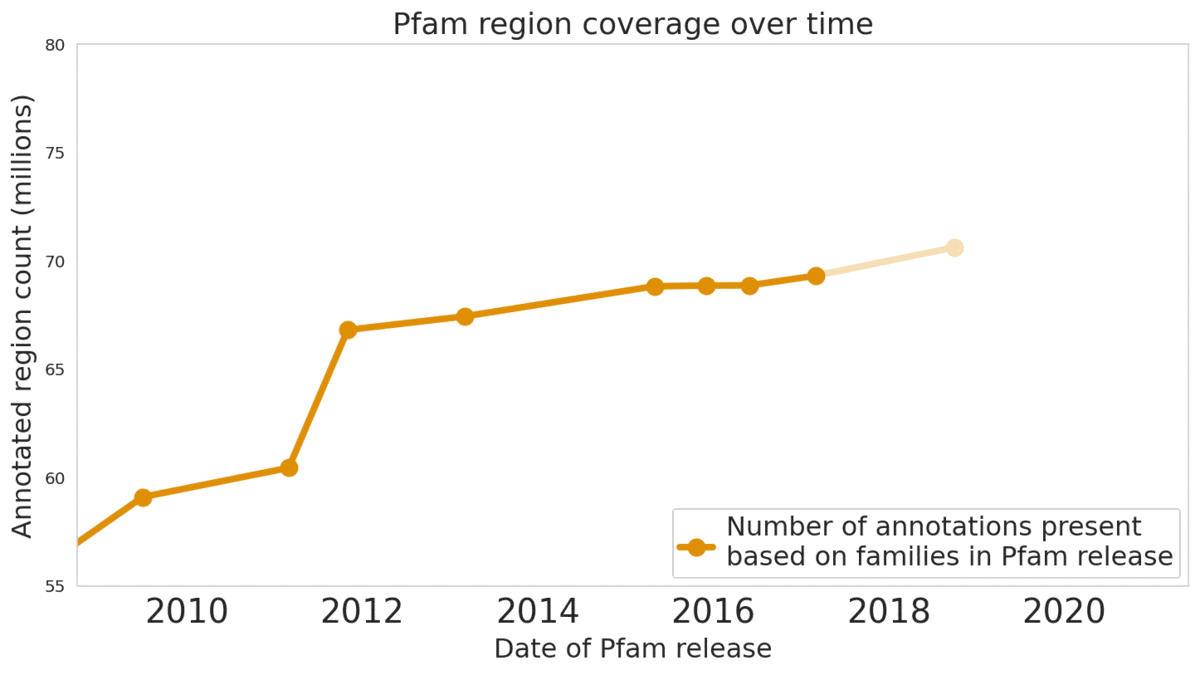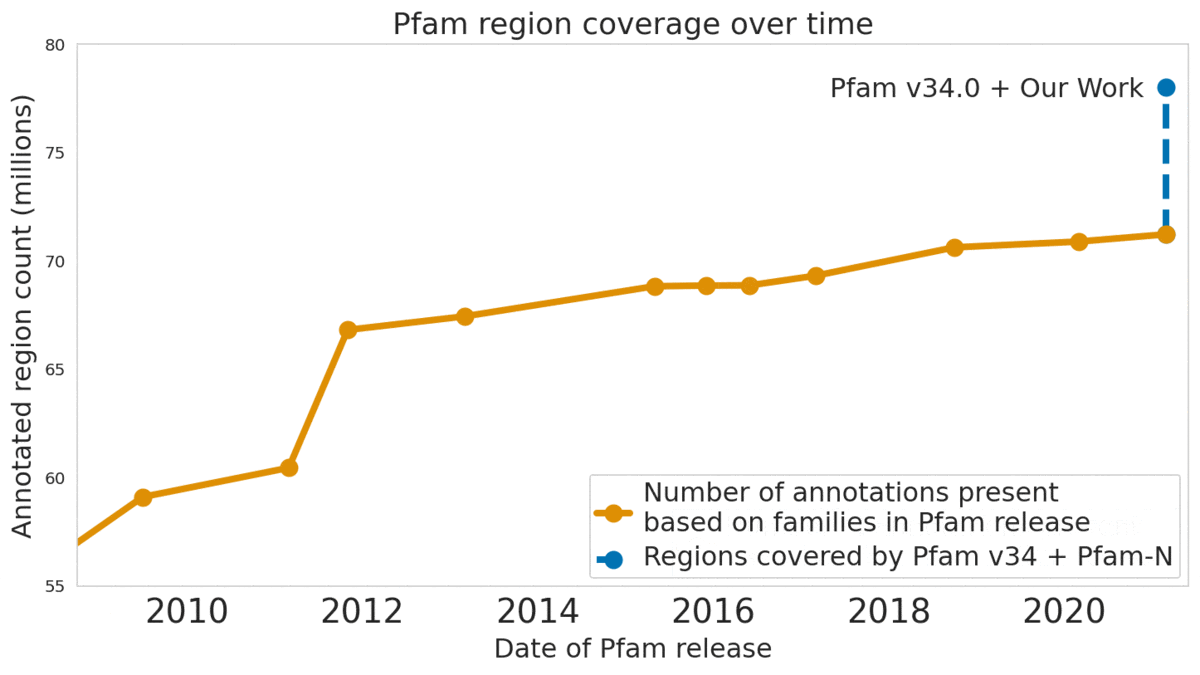
Pfam 数据库包含大量蛋白质家族及其测序
我们的机器学习模型帮助注释了数据库中的 680 万个蛋白质区域。
对此,谷歌表示,科学研究领域存在复制性危机,但仍希望可以成为解决方案的一部分。为了使谷歌团队的研究能被更广泛传播和使用,谷歌发布了一篇交互式科学文章(提供了一种使用神经网络从其氨基酸序列预测蛋白质功能特性的方法),浏览者可以在文中使用我们的机器学习模型 - 实时获得结果,所有这些都自动配置在用户的网络浏览器中,无需设置。
谷歌的使命是整合全球信息,供大众使用,使人人受益。让每位科学研究者都能平等地获取技术和有用的指导是这项使命的重要组成部分。这就是为什么谷歌一直致力于使这些模型变得有用且易于访问的原因。毕竟谁知道呢,其中一种蛋白质可以解开抗生素耐药性的解决方案就发生在我们眼前。


