
相比于人类讲话时丰富多变的语气,AI 语音的「心平气和」往往给人带来明显的违和感。
在人与人之间的对话中,即使是同样的字句,也会因为所处情景和情感的不同而表现出丰富的抑扬顿挫,而这种动态性恰恰是各种 AI 合成语音的「软肋」。相比于人类讲话时丰富多变的语气,AI 语音的「心平气和」往往给人带来明显的违和感。
如何让 AI 语音有效模仿人类对话的丰富动态与情感,已成为全球研究者的共同挑战。就在不久前,微软 AzureNeuralTTS(神经网络文本转语音)推出的新一代模型「Uni-TTS v4」在这一领域取得了里程碑式的重大突破。在「2021 国际语音合成大赛(Blizzard Challenge 2021)」的测试中,Uni-TTS v4 的语音表现与通用数据集上的自然语音相比几乎没有明显差别,展现出足以「叫板」真人对话的实力。
Uni-TTSv4 的研究出发点是 XYZ-代码,它是三种认知属性的联合表示:单语文本(X),音频或视觉感官信号(Y),以及多语言(Z)。关于这些努力的更多信息,请阅读 XYZ-代码的博文。https://www.microsoft.com/en-us/research/blog/a-holistic-representation-toward-integrative-ai/
「耳听」为实,让我们从以下几段 TTS 和真人对话的对比中,感受新模型带来的逼真语音表现。
En-US(Jenny):The visualizations of the vocal quality continue in a quartet and octet.
真人录音: https://www.microsoft.com/en-us/research/uploads/prod/2021/12/Jenny_NonTTS-recording.wav
Uni-TTS v4: https://www.microsoft.com/en-us/research/uploads/prod/2021/12/Jenny_TTS_new.wav
En-US(Sara):
Like other visitors, he is a believer.
真人录音: https://www.microsoft.com/en-us/research/uploads/prod/2021/12/Sara-NonTTS-recording.wav
Uni-TTS v4:https://www.microsoft.com/en-us/research/uploads/prod/2021/12/Sara-TTS-new.wav
Zh-CN(Xiaoxiao):
另外,也要规避当前的地缘局势风险,等待合适的时机介入。
真人录音: https://www.microsoft.com/en-us/research/uploads/prod/2021/12/Xiaoxiao-NonTTS-RECORDING.wav
Uni-TTS v4: https://www.microsoft.com/en-us/research/uploads/prod/2021/12/Xiaoxiao-TTS-NEW-Wave.wav
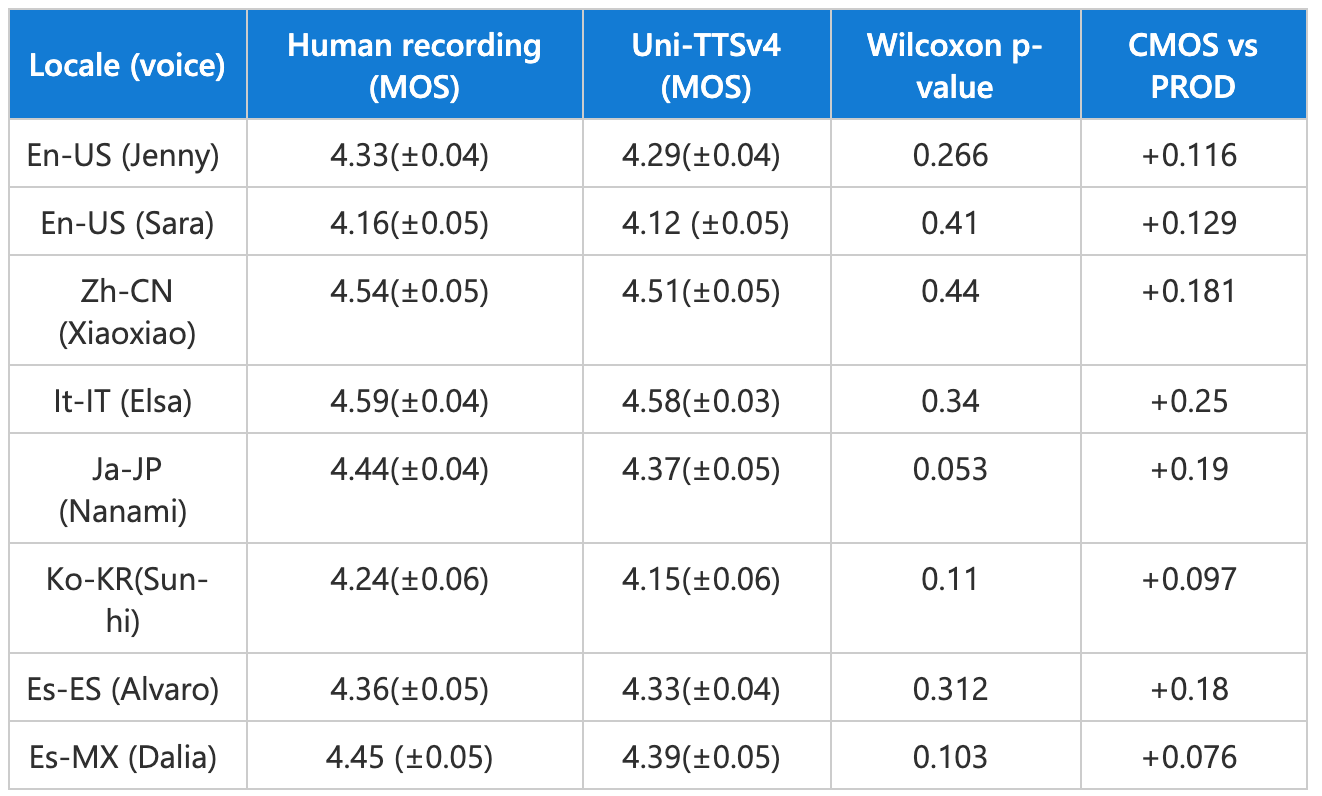
图注:上图为 Uni-TTS v4 在「2021 国际语音合成大赛(Blizzard Challenge 2021)」上的测试结果。这项 TTS 领域的全球盛事汇集了全球顶级专家,每次都会邀请数百名参会者对多个 TTS 系统进行大规模 MOS 测试,称得上是全球 TTS「试金石」。相关详细信息可以参看微软为此次活动发表的论文《DelightfulTTS: The Microsoft Speech Synthesis System for Blizzard Challenge 2021》。
如果体验完以上示例后还觉得意犹未尽,欢迎在 Azure TTS 在线服务中使用自创文本来创建新的 demo。目前 Uni-TTS v4 可支持 TTS 语言库中 7 个语种的 8 个语音,研发团队还将持续使用最新模型优化 Neural TTS 已支持的其它语言以及自定义神经语音,以便能让用户通过 Azure TTS API、 Microsoft Office 和 Edge browser 直接获得更出色的新一代 TTS 语音。
Uni-TTS v4 之所以能成为 AzureAI 的又一里程碑,在于其出色拟真语音表现的背后,对 TTS 语音基础建模的大幅革新。
如同开篇所说,TTS 语音与真人的差距在于难以模仿人类对话的丰富动态。人类在不同的情绪或场景下,对同一个词的发音方法可能完全不同,而且其变化规律在不同语种中也千差万别。
TTS 语音的表现依赖于以各种声学参数进行建模,但这些参数很难有效地对人类语音声学频谱上的所有粗粒度和细粒度细节进行建模。另一方面,TTS 是一种典型的一对多映射,往往需要使用多种语音风格(如音调、语速、讲话人、韵律、风格等等)来输出同一个文本内容。总之,能否为这些「变量」进行有针对性的建模,是提升合成语音表现力和真实度的重要因素。
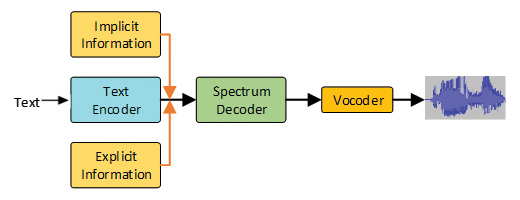
为了让 TTS 在以上两方面获得提升,Uni-TTS v4 在声学建模中引入了两项重要更新。通常,transformer 模型用来学习全局交互,而卷积神经网络则有效地发现局部相关性。于是研究团队首先采用了一个带有 transformer 和卷积块的新架构,以更好地模拟声学模型中的局部和全局依赖关系;其次,从显性视角(身份 ID、语种 ID、音调、语速)和隐性视角(话语级和音素级韵律)系统地对变量信息进行建模。这些视角分别使用监督学习和无监督学习,确保端到端的音频具有足够自然的表现力。

图注:Uni-TTS v4 的声学模型和声码器示意图。首先使用文本编码器对文本进行编码,然后将隐性和显性信息添加到文本编码器的隐藏嵌入(hidden embeddings)中,再使用频谱解码器预测梅尔声谱图。最后,通过声码器将梅尔声谱图转换为音频样本。
作为微软 Azure 认知服务中的强大语音合成功能,Neural TTS 可用于帮助开发者将文本转换为真人一般的逼真自然语音,常被用于语音助手场景、文字朗读功能,及作为辅助性工具等等,同时也被整合到微软的 Edge Read Aloud、Immersive Reader 和 Word Read Aloud 等旗舰产品中,还被 AT&T、Duolingo、Progressive 等众多客户采用。Neural TTS 已拥有 330 多个音色,支持来自不同国家和地区的近 130 种语言或方言。用户和企业可以通过搜索"Azure TTS"进入产品网站,测试体验 Neural TTS 的丰富预设语音,抑或录制并上传自己的样本,来创建独有的自定义语音。


