Graphcore 业界领先的科技现已开始面向全球出货。
2020 年 12 月 9 日,布里斯托——Graphcore 为其最新的 AI 计算系统——IPU-M2000 和纵向扩展的 IPU-POD64 发布了第一套性能 benchmark。
在各种流行的模型中,Graphcore 技术在训练和推理方面均显著优于 NVIDIA 的 A100(基于 DGX)。
亮点包括:
训练
·EfficientNet-B4:吞吐量高 18 倍
·ResNeXt-101:吞吐量高 3.7 倍
·BERT-Large:与 DGX A100 相比,在 IPU-POD64 上的训练时间快 5.3 倍(比双 DGX 系统缩短 2.6 倍)
推理
·LSTM:以更低时延实现吞吐量提升超过 600 倍
·EfficientNet-B0:吞吐量提升 60 倍/时延缩短超过 16 倍
·ResNeXt-101:吞吐量提升 40 倍/时延缩短 10 倍
·BERT-Large:以更低的时延实现吞吐量提升 3.4 倍
Benchmark 中包括了 BERT-Large(基于 Transformer 的自然语言处理模型)在 IPU-POD64 的全部 64 个处理器上运行的结果。
BERT-Large 的训练时间比最新的 NVIDIA DGX-A100 快 5.3 倍(比双 DGX 设置快 2.6 倍以上),这一结果彰显了 Graphcore 的 IPU-POD 横向扩展解决方案在数据中心的优势,以及 Poplar 软件栈管理复杂工作负载的能力,这些工作负载能够利用多个处理器并行工作。

Graphcore 软件高级副总裁 Matt Fyles 在对测试结果发表评论时说:「这一整套全面的 benchmark 表明 Graphcore 的 IPU-M2000 和 IPU-POD64 在许多流行模型上的性能均优于 GPU。」
「诸如 EfficientNet 之类的新型模型的 benchmark 特别具有启发性,因为它们证明了 AI 的发展方向越来越倾向于 IPU 的专业架构,而非图形处理器的传统设计。」
「客户需要能够处理稀疏性以高效运行大规模模型的计算系统,而这正是 Graphcore IPU 所擅长的。在这种客户需求的趋势下,差距只会不断扩大。」
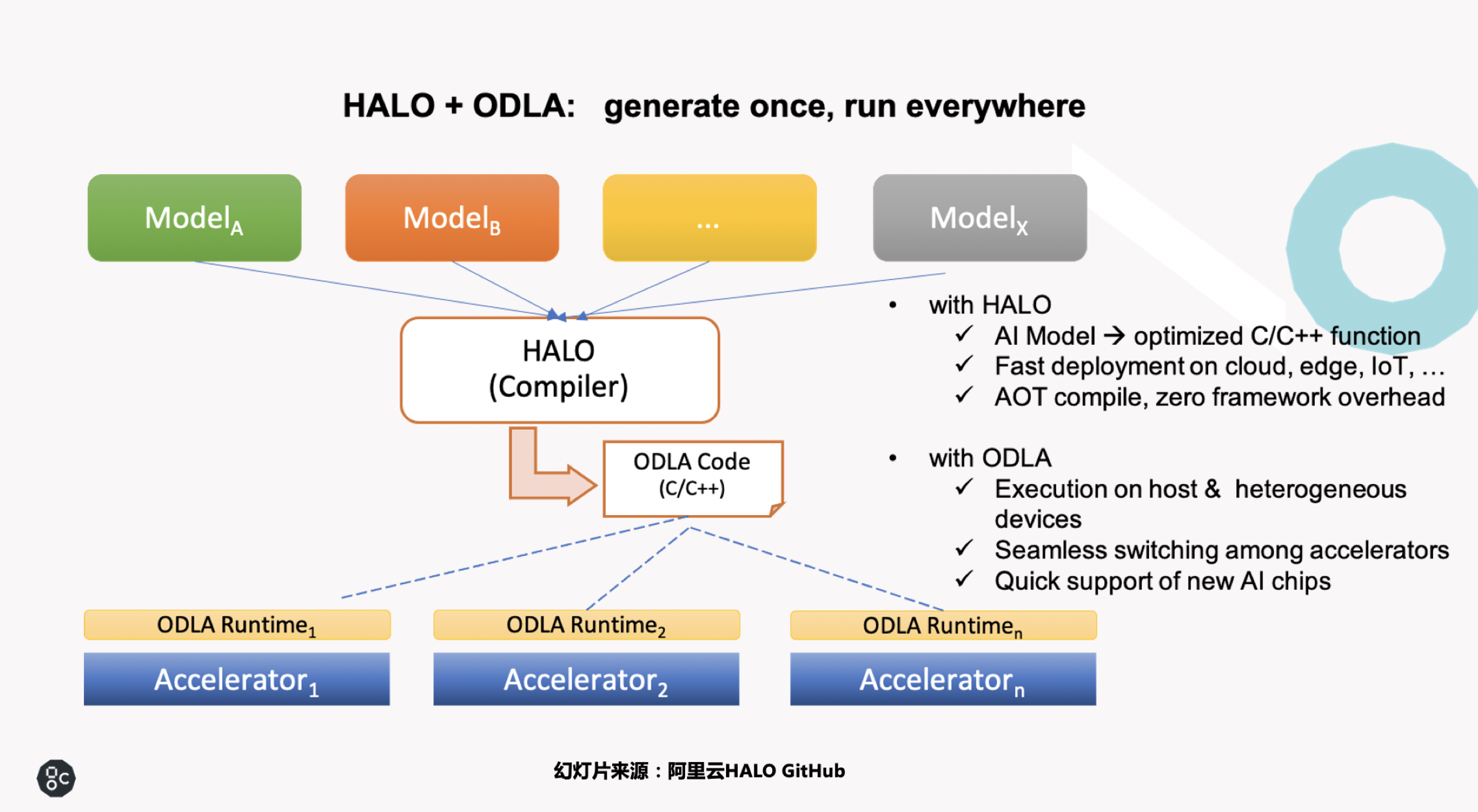
Graphcore为阿里云 HALO 定制代码正式在 GitHub 开源
Graphcore 是阿里云 HALO 的合作伙伴之一,为阿里云 HALO 定制开发的代码 odla_PopArt 已经在 HALO 的 GitHub 上开源,具体请见 https://github.com/alibaba/heterogeneity-aware-lowering-and-optimization
MLCommons
除了发布其 AI 计算系统的全面 benchmark 外,Graphcore 还宣布,其已经加入新成立的 MLPerf 下属机构 MLCommons,成为 MLCommons 的会员。
Graphcore 将从 2021 年开始参加 MLCommons 的比较 benchmark 测试。更多信息,请参阅 MLCommons 的成立公告。
PyTorch和Poplar 1.4
Graphcore 用户现在可以利用 Poplar SDK 1.4,包括全面的 PyTorch 支持。PyTorch 已成为从事尖端 AI 研究的开发人员的首选框架,在更广泛的 AI 社区中也收获了大批的追随者,并且追随者的数量还在快速增长。
PapersWithCode 的最新数据显示,在具有关联代码的已发表论文中,47% 的论文使用了 PyTorch 框架(2020 年 9 月)。
额外补充的 PyTorch 支持,再加上 Poplar 对 TensorFlow 的现有支持,这意味着绝大多数 AI 应用程序现在都可以轻松部署在 Graphcore 系统上。
与 Poplar 软件栈的其他元素一样,Graphcore 正在将其用于 IPU 接口库的 PyTorch 开源,从而使社区能够对 PyTorch 的开发做出贡献,并且加速 PyTorch 的开发。