

打败柯洁、功成名退的 144 天后,AlphaGo 再次刷屏的原因不再只是棋下得好那么简单。
2016 年 3 月,李世乭 1-4 败给了来自英国的围棋人工智能系统 AlphaGo。
2017 年 1 月 4 日,在取得了 59 场连胜之后,化名 Master 的神秘棋手在留言板上承认了自己的身份。
2017 年 5 月,在中国乌镇 ·围棋峰会上,AlphaGo 对阵人类世界排名第一的棋手柯洁,三局全胜。
以上就是 AlphaGo 在科技圈大规模刷屏的三次事件。
当其研发团队 DeepMind 在乌镇宣布 AlphaGo 正式退役时,所有人都以为这是一个创造了历史的围棋「棋手」传奇的结束,但没想到的是,2017 年 10 月 19 日的清晨,科技圈和围棋圈再一次,集体被 AlphaGo 刷屏。
从零开始纯自学的 AlphaGo
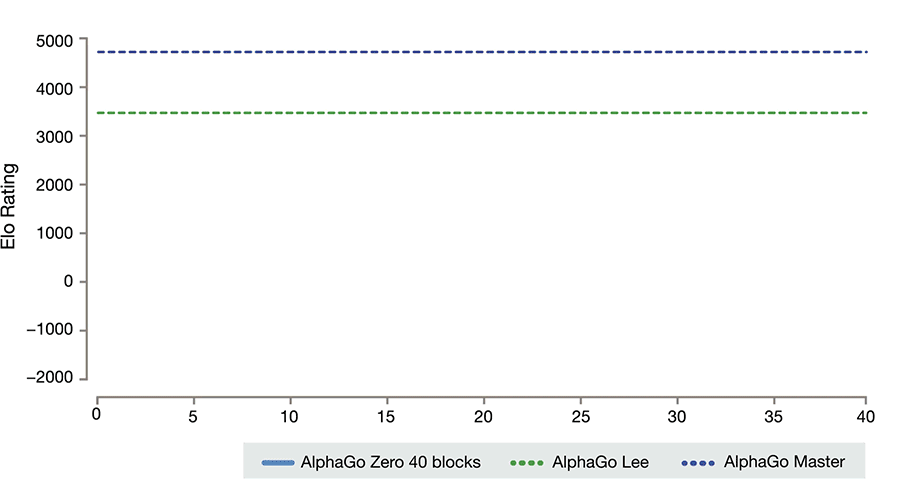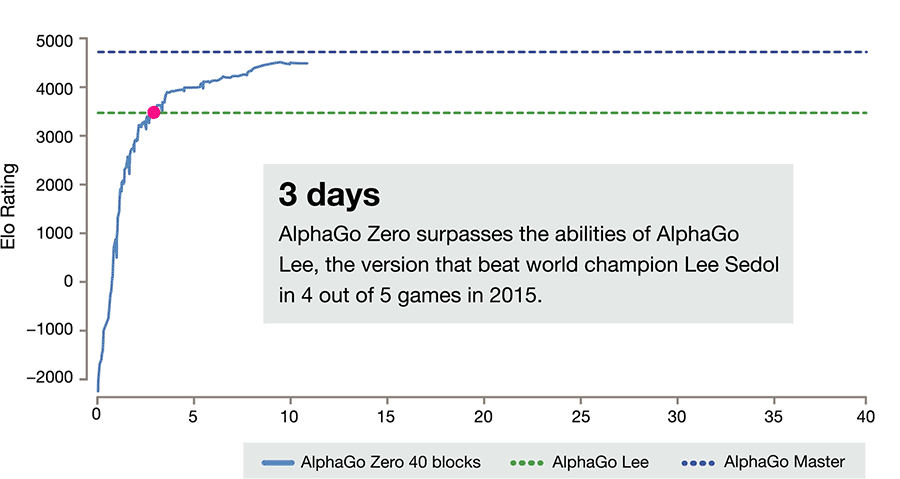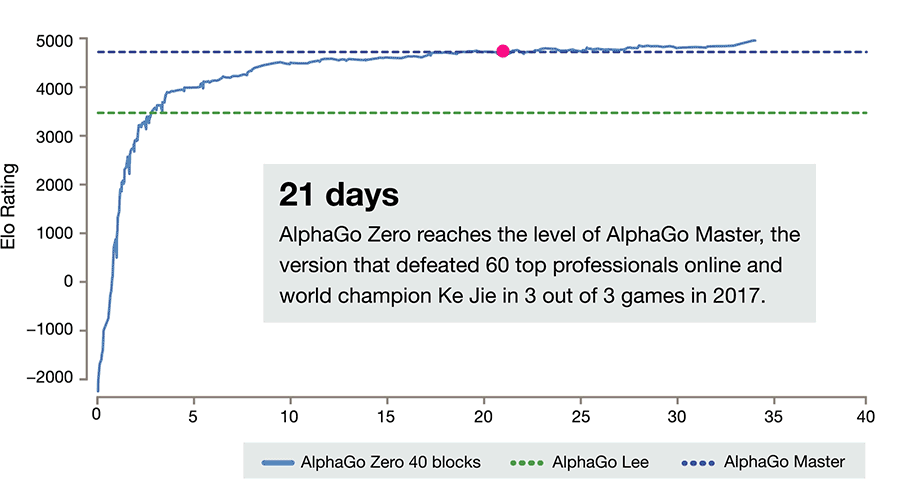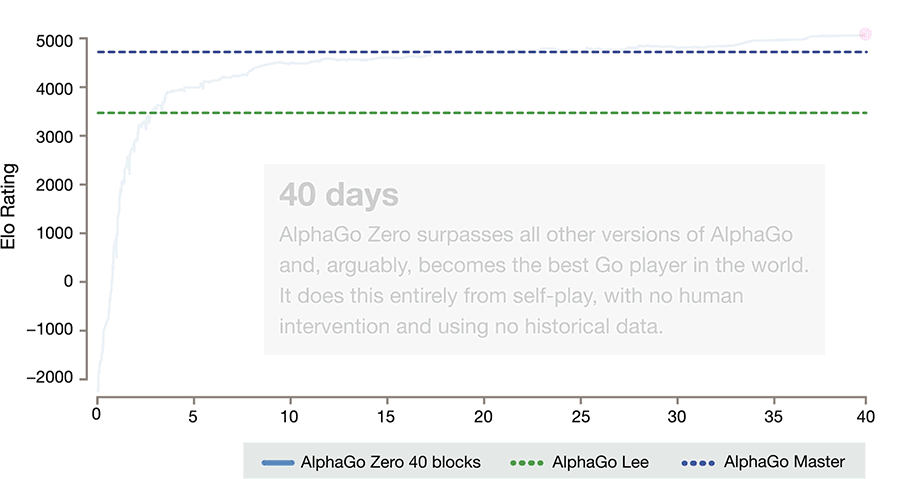
根据 DeepMind 的官方网站,AlphaGo 推出了最新的升级版,名为 AlphaGo Zero,这个版本完全依靠机器自己进行强化学习,在摆脱了大量的人类棋谱后,机器根据围棋的规则左右互搏,在三天之内就超越了去年三月对阵李世乭的版本,接着在第 21 天战胜了对阵柯洁的版本,到第 40 天,在对阵此前最先进的版本时,已经能保持 90% 的胜率。

DeepMind 官方表示,这毫无疑问是史上最强的围棋棋手。
但你也知道,仅仅是棋艺的升级不足以让它一夜之间霸占中外媒的头条,是什么让再次升级的 AlphaGo 吸引了这么多人的关注呢?
 柯洁和古力纷纷转发微博感慨机器的强大
柯洁和古力纷纷转发微博感慨机器的强大
DeepMind 在自己的官网上发表了一篇博客文章,同时表示新版本 AlphaGo 的研究论文已在权威学术期刊《自然》上发表。对学界来说,这是一个非常重磅的消息,总结来说这个版本特别的原因有三:
1、AlphaGo Zero 只使用围棋棋盘上的黑子和白子作为输入,而 AlphaGo 之前的版本中包含了少量人工设计的功能。
2、它使用的是一个神经网络而不是两个。AlphaGo 的早期版本使用「走棋网络(policy network)」来选择下一个动作和一个「价值网络(value network)」来预测游戏的赢家。AlphaGo Zero 合并了两者,使其能够更有效地进行训练和评估。
3、AlphaGo Zero 不使用「Rollout」——其他围棋程序使用的快速、随机的游戏来预测哪个玩家将从当前的棋局中获胜。相反,它依赖于高质量的神经网络来评估棋局。
以上这三点大大改善了 AlphaGo 的表现。
摆脱人类经验后下得更好
但 DeepMind 同时指出,是算法的改变让这个系统更加强大且高效。
72 小时自我对弈,AlphaGo Zero 就以 100-0 的成绩战胜了此前对阵李世乭的版本;40 天训练之后,它成功超越了击败柯洁的改良后的 Master 版本。
从下面的动图可以看到,因为从零开始的缘故,AlphaGo Zero 的初期表现非常糟糕,但水平提高的速度也非常快,仅仅三天就超越了对阵李世乭的版本。
「它比此前的版本更强大,是因为灭有使用人类的数据,也不使用任何形式的人类经验,我们已经消除了人类知识的局限,它能够创造知识本身,」AlphaGo 的首席研究员 David Silver 说道。
这个系统通过强化学习来提高它自身的技巧水平。每当 AlphaGo Zero 走了一步好棋时,它就会获得系统的「奖励」,反之则有损失。
系统的核心是一组软件上的「神经元」,这些「神经元」连接在一起,形成一个人工的神经网络。在游戏的每一个回合中,神经网络会查看棋盘上棋子的位置,然后计算下一步棋的位置,并计算出每一步的可能性,做出最可能获胜的选择。在每一场比赛之后,它会更新它的神经网络,使它在下次比赛中更加强大。
尽管比以前的版本好得多,但 AlphaGo Zero 其实是一个更简单的系统,它需要的数据更少,硬件要求也更低(对阵李世乭的 AlphaGo 使用了 48 个 TPU,而 AlphaGo Zero 只用了 4 个 TPU),但它仍能够更快地掌握游戏。Silver 表示,如果有更多的时间,它甚至可能会发展出一套自己的规则。

根据一些外国棋手的观察,AlphaGo Zero 在棋局的初期表现仍与人类千年来的套路相同,但到棋局中期就会变得令人难以理解。
围棋之外,AlphaGo 还能带来更多
这也是这次 AlphaGo 再次刷屏的原因之一。身为该研究重点的强化学习是机器智能领域一个非常重要的技术,它从深度学习中延伸出来,进一步摆脱人类的干涉训练机器,而 DeepMind 也一直致力于「深度强化学习(Deep Reinforcement Learning)」的研究。
此前他们就发表了一篇论文,研究如何让一个 AI 系统自学「跑酷」。该 AI 系统在没有输入人类经验的前提下学习翻越障碍物,最终发展出自己翻越的方法。
机器能够发现人类无法发现的一些东西,这在人工智能界是一个普遍的共识,早先就有人颇为异想天开地尝试让人工智能根据图片来辨别人的性取向,虽然这样的研究遭到了不少的批评,但它确实反映了人工智能研究者们对 AI 的一些期待。
人类自己的知识是有局限的,而本质是计算机程序的人工智能往往与大多数人类的视角不同,他们能够在人类的固有思维和司空见惯的事物中发现人类找不到的规则和破解问题的方法。
AlphaGo Zero 就是一个很好的证明。
所以让 AlphaGo Zero 再次刷屏的并不是它多强的围棋技巧,也不是「100-0」、「3 天」和「40 天」这样惹人眼球的数字,而是它所证明的技术理论的可行性。
在围棋以外,得到论证的理论其实还能做到更多。
「尽管目前仍处于早期阶段,但 AlphaGo Zero 构成了朝着这个目标迈进的关键一步。如果类似的技术可以应用到其他结构问题上,比如蛋白质折叠、减少能源消耗或者寻找革命性的新材料时,那么这些突破就有可能对社会产生积极的影响。」DeepMind 在官方博客中如此说道。
所以,有关「让机器下围棋,下得再好又有什么用」的看法其实是非常幼稚的。
当 DeepMind 和 OpenAI 等公司开始研究让 AI 打 Dota、星际争霸等游戏时,收获的往往也是社会上的嘲笑声。
在大多数人的设想中,他们希望人工智能帮他们开车、打扫房间、完成这样那样简单且重复性的工作。事实上,这也是那些拥有着最顶尖技术的科技公司想要的,但在达到这些终极目标之前,他们也需要棋牌、游戏等训练算法的土壤,在这些模拟的棋局、比赛中,打造 AI 系统的模拟器(simulator),这也是为什么当 DeepMind 表示要挑战星际争霸时,他们表示这会比围棋更有挑战性——因为 MOBA 类游戏的场景更加复杂。
头图来源:视觉中国
责任编辑:王伟


